La décomposition de l'indicateur de Gini en sous-groupes
Pages 179 à 243
Citer cet article
- MORNET, Pauline,
- MUSSARD, Stéphane,
- SEYTE, Françoise
- et TERRAZA, Michel,
- Mornet, Pauline.,
- et al.
- Mornet, P.,
- Mussard, S.,
- Seyte, F.
- et Terraza, M.
https://doi.org/10.3917/rfe.142.0179
Citer cet article
- Mornet, P.,
- Mussard, S.,
- Seyte, F.
- et Terraza, M.
- Mornet, Pauline.,
- et al.
- MORNET, Pauline,
- MUSSARD, Stéphane,
- SEYTE, Françoise
- et TERRAZA, Michel,
https://doi.org/10.3917/rfe.142.0179
Notes
-
[1]
Ces deux types de répartitions ne sont pas totalement cloisonnés. Cf. les travaux de Dagum [1999] sur le lien qui prévaut entre la répartition personnelle et la répartition fonctionnelle du revenu.
-
[2]
Cf. les travaux de Theil [1967].
-
[3]
Techniquement, il mesure deux fois l’aire contenue entre la première bissectrice et la courbe de Lorenz.
-
[4]
Notamment des riches vers les pauvres.
-
[5]
Parmi les propriétés axiomatiques de base telles que la continuité, le principe de transfert de Pigou-Dalton, le principe de population de Dalton, la symétrie, la normalité ou encore l’invariance relative, nous insistons sur le respect du critère de transfert car ses implications sont importantes pour les politiques socio-économiques de redistribution. Mais depuis les travaux de Bourguignon [1979], Cowell [1980a, 1980b], Shorrocks [1980, 1984, 1988] et Ebert [1988, 2010] la décomposition est devenue tout aussi essentielle car elle permet de préciser les déterminants des inégalités au sein d’une population - étape primordiale avant d’effectuer des transferts redistributifs.
-
[6]
Les transferts sont valables, que les individus conservent ou non leur rang dans la distribution.
-
[7]
Cette propriété suscite un intérêt particulier et controversé, car certaines mesures ne satisfont pas l’invariance relative mais l’invariance dite absolue. Autrement dit, les inégalités de revenu ne sont pas affectées lorsque l’on octroie la même somme à chaque individu. Mais la littérature montre que l’on abandonne progressivement ces deux axiomes pour des concepts intermédiaires.
-
[8]
En d’autres termes, toute mesure additivement décomposable respecte la propriété d’agrégativité mais la réciproque est fausse. On peut notamment citer trois mesures qui sont reconnues pour être agrégatives mais non décomposables, il s’agit du coefficient de variation, de la mesure d’Atkinson ou encore du critère de Rawls.
-
[9]
Exception faite du second indicateur de Theil, de la variance des logarithmes et de la déviation logarithmique moyenne.
-
[10]
L’auteur ne donne pas de définition du terme cjh, mais intuitivement on comprend qu’il s’agit du coefficient de Gini entre les groupes j et h. Cette idée sera notamment reprise par Dagum [1987, 1997a] dont la décomposition est issue de la spécification des indicateurs de Gini intragroupes et intergroupes.
-
[11]
La diagonale de la matrice est composée des coefficients de Gini mesurés sur chaque groupe cjj.
-
[12]
Cette condition vient s’opposer à celle qui prévaut pour les mesures de l’entropie généralisée dont la décomposition en sous-groupes conduit à des termes intergroupes qui ne sont nuls que si et seulement si la moyenne intragroupe est égale à celle de tous les autres groupes.
-
[13]
Cette seconde formulation peut être prouvée en utilisant le lemme 2.1 de Baringhaus et Franz [2004] et peut également être assimilée à un « co-moment » entre le rang de la fonction de répartition F(y) et sa fonction inverse 1-F(y) rapporté à la moyenne de la distribution.
-
[14]
Dans son article de 2009 Okamoto précise que le coefficient de variation de Cramér correspond au surplus de la dispersion relative à la proportion de fusion quand a lieu la fusion d’une infiniment petite proportion de fusion du groupe i.
-
[15]
La courbe de Lorenz est un cas particulier de la courbe de concentration. Voir la généralisation de Pyatt, Chen et Fei [1980].
-
[16]
Il a été montré que le coefficient de Gini ou la valeur ?/2? correspondent à deux fois l’aire entre la courbe de Lorenz et la première bissectrice du carré de côté unitaire.
-
[17]
La composante intragroupe est issue ex post de la détermination de la moyenne des différences de Gini globale et de la moyenne des différences de Gini intergroupe.
-
[18]
Rappelons que Rao a décomposé l’indicateur en un élément intragroupe et un élément qui explique les différences de revenu entre les diverses classes des sous-groupes. Das et Parikh [1982] montrent que Bhattacharya-Mahalanobis et Pyatt spécifient d’abord les inégalités intergroupes et dérivent ensuite l’inégalité intragroupe comme un résidu, alors que Rao spécifie la composante intragroupe et dérive l’élément intergroupe comme un résidu (néanmoins défini comme les différences entre les classes (cij)) au même titre que les décompositions de Soltow [1960] et Mangahas [1975].
-
[19]
Si la population mère est composée de trois groupes, la décomposition s’écrit : G = a1G1 + a2G2 + a3G3 + GB + R.
-
[20]
Cf. l’approche de Milanovic et Yitzhaki [2002] pour une application internationale.
-
[21]
L’indice étudié par Yitzhaki [1994] diffère néanmoins de celui proposé par Lerman et Yitzhaki [1991]. L’auteur choisit de baser son indice de chevauchements non plus sur les rangs mais sur les distributions cumulatives. De plus, l’indice capte également les chevauchements éventuels au sein même d’un groupe.
-
[22]
La littérature sur les distances entre les distributions s’est développée notamment avec les travaux de Dagum [1980], Shorrocks [1982], Ebert [1984], Chakravarty et Dutta [1987], Yitzhaki [1994], et Deutsch-Silber [1997]. Il est aussi possible de s’intéresser à la critique de Shorrocks [1982] concernant la mesure de Dagum [1980] et à la réponse de Dagum [1997a, p. 519]. Shorrocks [1982] montre que la mesure de Dagum ne reflète pas une distance euclidienne. Or, Dagum [1997a] fait remarquer à Shorrocks qu’il s’agit d’une distance économique directionnelle conformément à la définition de 1980, conduisant Shorrocks à une erreur d’interprétation fondamentale (voir aussi la critique de Yitzhaki [1994] sur la distance D1 de Dagum).
-
[23]
Pour une application de cette décomposition cf. Mussard, [2004].
-
[24]
Cf. Sala-i-Martin [1996] pour une approche synthétique.
-
[25]
Un indice d’inégalité I(.) est strictement S-convexe si I(X)>I(AX) avec A une matrice bi-stochastique (qui n’est pas une matrice de permutation) et X le vecteur de revenu. Cette propriété réunit l’anonymat ainsi que le principe de transfert progressif et permet entre autre de rendre la mesure de convergence cohérente avec le critère de dominance de Lorenz quand la moyenne de la distribution ne varie pas.
-
[26]
Nous pouvons notamment citer Wodon [1999] qui proposa une méthode de décomposition en multi-niveaux basée sur la décomposition en sous-groupes introduite par Lerman et Yitzhaki [1991] qui présente la troisième composante comme un indice de stratification. Esteban [2000] exploita également les propriétés du Gini afin de calculer des polarisations entre les groupes.
« Connaissance créée et non transmise devient stérile et risque de disparaître, connaissance créée et transmise doit être mise au service de la communauté pour contribuer au renforcement de l’efficacité, de l’équité, de la préservation de l’écosystème et du respect total de la liberté. »
1L’économie des inégalités est une partie non négligeable de l’économie publique et du domaine de la justice sociale. Pour apprécier l’efficacité d’un principe de justice sociale (commutative, distributive, locale, etc.), les mesures d’inégalité sont souvent utilisées. Elles permettent notamment de déterminer l’intensité de l’efficacité d’une mesure de justice sociale (ou de politique économique redistributive). Les indicateurs d’inégalité forment donc un préalable aux prises de décisions publiques concernant les politiques socio-économiques.
2Cet article repose uniquement sur l’aspect des mesures de l’inégalité du revenu. Cette partie de l’économie publique issue de la théorie de la répartition du revenu est constituée de deux notions distinctes : la répartition fonctionnelle du revenu et la répartition personnelle du revenu. [1]
3La démarche que nous adoptons appartient au domaine de la répartition personnelle du revenu. Plus précisément, il s’agit de l’approche par les indices de mesure des inégalités, notamment impulsée par les travaux de Kolm [1966], Atkinson [1970] et Sen [1973]. Ce domaine s’attache à mesurer l’intensité des inégalités de revenu entre les individus d’une même population afin de savoir si ces disparités sont jugées importantes ou non. La valeur de l’indice indique donc le caractère égalitaire ou inégalitaire de la répartition des revenus.
4L’approche par les indices est différente de celle de la modélisation des distributions de revenu, qui tente d’adapter un modèle paramétrique de nature économétrique aux revenus observés. L’approche par les distributions autorise l’évaluation des inégalités en interprétant l’intensité et l’évolution des paramètres d’un modèle estimé. Il s’agit d’estimations paramétriques des disparités de revenu dont Pareto [1896] est l’un des précurseurs. On recense par la suite les modèles de Champernowne [1952] ou encore de Singh et Maddala [1976]. Les modèles de Dagum [1977] sont de nos jours les plus robustes et leur spécification, issue des travaux de Pareto, puise dans une recherche de cohérence à la fois économique et économétrique.
5Ces méthodes paramétriques ont été de plus en plus accompagnées d’estimations non paramétriques portant sur les indices d’inégalité. Ces indices, simples d’interprétation car souvent compris entre zéro et un, autorisent des comparaisons entre populations. L’estimation par les indices permet d’expliquer la totalité des inégalités de revenu observées, sans perte d’information. Il est cependant nécessaire de vérifier les différentes propriétés qu’ils intègrent.
6L’indice de Gini [1921] est, avec les mesures de la famille de l’entropie généralisée, [2] l’un des plus utilisés. Il est compris dans l’intervalle [0 ;1] et possède la particularité d’être issu de la courbe de Lorenz [1905]. [3] Il mesure les inégalités de répartition de revenu et la concentration d’une distribution. De plus, l’indicateur de Gini permet d’étudier l’impact des transferts de revenu. [4] Sa structure va, par conséquent, être liée aux politiques de redistribution qu’il est possible d’effectuer au sein d’une population afin de parvenir à un meilleur niveau d’équité. L’indicateur de Gini possède donc des propriétés intéressantes, qui incluent la propriété de décomposition.
7Pour décomposer un indicateur en sous-groupes, il est nécessaire que la population globale P soit divisée en plusieurs groupes (par exemple hommes et femmes, catégories socioprofessionnelles, régions, groupes d’âge, etc.). La finalité d’une décomposition en sous-populations est d’expliquer les inégalités de revenu par le degré d’implication des différents groupes composant P. Est-ce qu’un groupe participe plus qu’un autre à l’explication des inégalités ? Il s’agit de la première question à laquelle la décomposition peut répondre. Mais pourquoi peut-on privilégier ces approches multi-variées aux approches standard non décomposées ?
8L’approche non décomposée permet de comparer différents indices, s’ils sont normalisés. Cette comparabilité autorise un classement des différentes sous-populations en spécifiant les inégalités qui y prévalent. En revanche, outre ce classement, la décomposition permet de définir les groupes qui possèdent les plus fortes contributions à l’explication de l’inégalité totale. D’autre part, la décomposition ne se limite pas à la seule mesure des inégalités à l’intérieur de chaque groupe car la décomposition admet le calcul des disparités de revenu entre les individus appartenant à des groupes différents. Par conséquent, le procédé de décomposition autorise l’estimation des inégalités à l’intérieur de chaque groupe (mesures intragroupes) et des inégalités entre les différents groupes (mesures intergroupes). Les questions auxquelles les décompositions peuvent répondre sont les suivantes : quelle est la part d’inégalité intergroupe dans l’inégalité totale, quelle est la contribution des inégalités intragroupes à l’inégalité totale, quelle est la participation d’un groupe précis à l’inégalité totale ou encore quelle est la contribution des inégalités entre deux groupes précis à l’inégalité totale ?
9Les méthodes de décomposition en multi-niveaux sont une extension directe des méthodes de décomposition en sous-groupes. Chaque sous-groupe constitue alors une sous-population dans laquelle s’appliquent les mêmes règles de décomposition que celles qui prévalent sur la population mère. Ces méthodes de décompositions en multi-niveaux offrent une analyse plus performante des déterminants des inégalités et permettent d’élargir le champ d’étude à plusieurs dimensions.
10L’économie des inégalités réunit par ailleurs trois approches : l’approche positive, l’approche normative et l’approche axiomatique. La propriété de décomposition s’inscrit dans l’approche axiomatique. Certaines phases de notre recherche font donc appel à l’axiomatique [5] et, dans une moindre mesure, au normatif. Néanmoins, l’indicateur d’inégalité reflète des normes particulières. Notre champ d’analyse (l’approche par les indices décomposables) est par conséquent connexe à l’approche axiomatique, normative, et positive.
11La décomposition en sous-groupes (ou plus largement en multi-niveaux) est donc une propriété fondamentale. Cependant, toutes les mesures d’inégalité ne sont pas munies de cette propriété. L’essence même de cette décomposition repose sur des aspects mathématiques précis, comme la séparabilité additive d’une fonction. Il est donc intéressant d’étudier les propriétés issues des mesures décomposées, et en particulier le coefficient de Gini.
12Dans cette recherche, nous exposons les principales méthodes de décomposition en sous-groupes de l’indice de Gini qui ont pu être formulées à partir des années 1960 jusqu’à nos jours. Notre développement ne manque cependant pas de mentionner certaines méthodes visant à décomposer d’autres indicateurs que celui de Gini afin d’offrir une meilleure compréhension des enjeux que recouvre la décomposition de cet indicateur. Nous commençons par rappeler les principes axiomatiques sous-jacents à chacune de ces méthodes avant de présenter les différentes décompositions. Dans une deuxième section nous proposons une rapide synthèse des travaux de Bourguignon [1979] et Shorrocks [1980, 1984, 1988] afin d’introduire un certain nombre de concepts de base généralement rattachés à la notion de décomposition en sous-groupes, tels que l’additivité, l’agrégativité ou encore la cohérence en sous-groupes. Nous faisons mention dans une troisième section des méthodes de décomposition alternatives qui ont pu être proposées pour pallier le problème de dépendance identifié entre les composantes issues de la décomposition additive. Une quatrième section est ensuite consacrée aux méthodes de décomposition selon deux composantes de l’indice de Gini. Au cours de cette section, nous mettons notamment l’accent sur la composante intragroupe qui joue un rôle particulier dans les décompositions mentionnées. Les méthodes de décomposition de l’indice de Gini selon trois composantes sont présentées dans la cinquième section. Chacune des méthodes évoquées fait référence à une des différentes étapes liées à l’identification de cette troisième composante ainsi qu’à son interprétation. La sixième section regroupe deux des plus grandes généralisations du concept de décomposition en sous-groupes : la décomposition faible et la notion de décomposition en multi-niveaux. Une septième et dernière section apporte des éléments de conclusion.
Rappels sur les principaux axiomes
La continuité
13L’indice d’inégalité est une fonction continue :

15où ?n, ?+ et N sont respectivement l’ensemble des réels de dimension n, l’ensemble des réels non négatifs et l’ensemble des entiers naturels.
Le principe de population de Dalton
16Le principe de population prévoit qu’un indice reste inchangé lorsque la population s’accroît de manière identique. Si chaque individu d’une population se retrouve avec une personne ayant le même revenu, les inégalités restent inchangées. Pour une distribution x = {x1, x2, …, xn} que l’on réplique k fois :
17![Description de l'image par IA : Formule mathématique avec une somme de k à n. X égal à la somme de X[i] de k à n, répété de k à n.](https://shs.cairn.info/article/RFE_142_0179/image/full/im2?lang=fr)

Le principe de transfert de Pigou-Dalton
19Un transfert engendre la baisse d’un indice (diminution des inégalités au sein de la société) lorsqu’un individu riche reverse une partie de son revenu à une personne moins riche que lui. [6] Inversement, l’indice augmente (caractérisant une augmentation des inégalités au sein de la société) quand un transfert est pratiqué d’une personne pauvre vers une personne riche. Si une distribution x est obtenue à partir d’une distribution y où l’on effectue un transfert de revenu progressif (d’une personne riche vers une personne pauvre), alors la mesure des inégalités associée à x devient plus faible que celle associée à y :

21De manière plus générale, il est possible d’exprimer un transfert de revenu progressif entre deux individus à l’aide d’une matrice de transfert T. Ainsi, la distribution x obtenue à partir de la distribution y sur laquelle un transfert progressif a été opéré se note également :

23où 0 ? ? ? 1, I est la matrice unité et Pij est la matrice de permutation associée à la transposition des indices i et j.
24Si, de plus, la matrice T est une matrice carrée symétrique d’éléments génériques tij tels que :
25
26
27Cette dernière formulation définit la notion de S-convexité introduite par Schur en 1923. Ainsi comme l’ont montré Hardy-Littlewood et Polyà [1934], les deux notions de transferts progressifs et de S-convexité sont équivalentes.
La symétrie (anonymat)
28Cette propriété montre qu’un indice est invariant lorsque le rang d’un individu dans la distribution est modifié. Par exemple, si l’on introduit une perturbation dans la distribution (en classant les revenus par ordre croissant ou décroissant), la mesure d’inégalité doit conserver la même valeur. Ce principe désigne la propriété d’un indice invariant après permutation de l’ordre des individus ou encore permettant à chacun de conserver son anonymat. Si x est obtenu à partir de y par permutation des revenus, on obtient une fonction symétrique de ses arguments :

30Il est désormais possible de compléter la définition précédente. En effet, si la matrice de transfert T est symétrique et bistochastique, les transferts de revenus qui s’opèrent sur la distribution y ont la particularité de conserver l’anonymat des individus. Les transferts ainsi générés sont donc de type Pigou-Dalton.
La normalisation
31Elle autorise la comparaison d’indices d’inégalité compris dans l’intervalle [0 ;1]. Si l’indice tend vers 0 les revenus sont répartis de manière égalitaire ; en revanche, si l’indicateur tend vers 1 la répartition est jugée inégalitaire. Plus communément, on associe la normalisation à la condition suivante :

33où 1n est le vecteur unité de dimension n (vecteur dont les éléments sont tous égaux à 1). Il s’agit de la condition selon laquelle les indices d’inégalité prennent la valeur 0 pour des distributions égalitaires.
34L’ensemble formé par les mesures qui satisfont les axiomes (CN), (PD), (PP), (SM) et (NM) est appelé ensemble des indices réguliers. D’autre part, en ajoutant la propriété d’invariance relative, on peut définir la classe des indices réguliers relatifs.
L’invariance relative
35La propriété d’invariance relative stipule que lorsqu’une population voit ses revenus multipliés par un nombre supérieur à zéro (par exemple multipliés par deux) alors les inégalités restent inchangées. [7] La propriété d’invariance relative, reflétant une fonction homogène de degré zéro, s’exprime sous la forme :

37Autrement dit, les mesures relatives ne sont pas affectées par une augmentation proportionnelle des revenus. Si les inégalités sont mesurées sur des revenus exprimés en francs ou bien sur ces mêmes revenus exprimés en euros, l’indice d’inégalité procure le même résultat.
38Ces différents axiomes caractérisent l’indice de Gini et lui confèrent des propriétés intéressantes qui vont faciliter la mise en œuvre de sa décomposition en sous-groupes.
39Ces quelques rappels étant faits, nous pouvons à présent consacrer notre développement aux diverses méthodes de décomposition qui se sont développées au fil des ans.
40En 1912, Gini établit une relation remarquable entre un indice d’inégalité et la différence moyenne relative. Il montre, en effet, que son indicateur est toujours égal à la moitié de la différence moyenne relative que l’on qualifie aujourd’hui de différence moyenne de Gini (GMD). Ses premiers travaux publiés en italien restent méconnus de bon nombre de chercheurs jusqu’en 1921, quand il rédige une note en anglais visant à commenter l’article de Dalton [1920] et à présenter ses recherches. Plusieurs formulations alternatives de l’indice de Gini se développent alors, en faisant appel à différentes approches telles que l’approche géométrique, l’approche matricielle ou encore l’approche par la covariance. L’indice de Gini apparaît progressivement comme une mesure agrégeable, qui se révèlera par la suite être décomposable. Cet indicateur ne fait cependant pas l’unanimité auprès des chercheurs. Cela ne va certes pas empêcher la parution de nombreuses méthodes de décompositions en sous-groupes pour cet indice. Dans le même temps se développent des méthodes de décomposition qui visent d’autres indicateurs et dont la structure repose sur deux composantes principales. Ces décompositions sont souvent considérées comme les concepts de base de la décomposition en sous-groupes et sont exposées dans le paragraphe suivant.
Concepts de bases
41Les premières recherches sur les mesures d’inégalité décomposables sont des tentatives d’axiomatisation qui tendent à dériver ou à créer certains indices. Bourguignon [1979] est le premier à proposer des propriétés de généralisation et à définir les notions clefs de l’agrégativité et de l’additivité. Ces notions ont ensuite été reprises et approfondies par Shorrocks [1980, 1984, 1988] afin d’être compatibles avec la classe entière des mesures de l’entropie généralisée.
Définitions
42Soit une population de n individus (i = 1,…,n) partitionnée en k sous-populations (groupes d’âge, régions, niveau d’éducation, etc.). Chaque sous-population est de taille nj (j = 1,…,k). On note le revenu de l’individu i du groupe j : xij. Le vecteur de revenu global est défini par : x = (x11,x21,…,xij,…,xnk).
L’agrégativité
43Une mesure agrégative est définie par :

45où I est l’indice d’inégalité associé à la population globale, I1 l’indice d’inégalité associé au groupe 1 et Yj la somme des revenus de la sous-population j :

47L’agrégativité est une propriété générale indiquant qu’il n’est pas nécessaire de connaître les caractéristiques exactes des distributions des sous-groupes pour déterminer le montant des disparités de revenu. Les mesures d’inégalité de chaque sous-population et les éléments agrégés tels que n1 et n1?1 sont simplement nécessaires. Les mesures d’inégalité agrégatives vérifient la décomposition élémentaire suivante :

49où Fk {0,…,0 ; Y1,Y2,…,Yk ; n1,…,nk} est un terme désignant une inégalité associée à des groupes égalitaires. Il est par conséquent possible de formuler les inégalités à l’intérieur des groupes et les inégalités entre les groupes. La contribution des inégalités intragroupes (Iw) à l’inégalité totale est définie comme la différence entre les inégalités observées dans la population mère et celles qui seraient effectivement observées si les individus du groupe j avaient tous le même revenu :

51La contribution des inégalités intergroupes à l’inégalité totale est :

53La décomposition en sous-groupes de la mesure d’inégalité est :

55Pour définir les inégalités à l’intérieur d’un groupe précis, on effectue la même opération que pour Iw. La contribution des inégalités associées au groupe j à l’inégalité totale s’écrit :

57Cette définition peut paraître paradoxale, car la somme des contributions de chaque groupe Iwj n’est pas forcément égale à Iw. Les mesures ne sont donc pas indubitablement additives.
L’additivité
58Une mesure d’inégalité est additivement décomposable si elle vérifie la relation :

60Les mesures additivement décomposables sont donc agrégatives. L’additivité apparaît comme une propriété plus fine : un cas particulier de l’agrégativité. Les inégalités de revenu d’une population peuvent être exprimées comme des fonctions des inégalités à l’intérieur des sous-groupes et des caractéristiques agrégées de la population mère. Cette définition correspond en quelque sorte à une propriété d’agrégativité qui permet de décomposer les inégalités totales selon diverses composantes. Cependant, la décomposition nécessite une condition un peu plus forte que celle d’agrégativité, elle requiert l’additivité. [8]
61Ainsi, les mesures additivement décomposables sont des indicateurs d’inégalité qui s’écrivent sous la forme d’une moyenne pondérée des indices associés à chaque groupe (Ij) à laquelle on ajoute l’indicateur d’inégalité intergroupe. Mais il existe également des mesures décomposables qui sont séparables en pondérations de populations (où le poids est la proportion de population du groupe j : nj / n). Ainsi que des mesures où les pondérations font intervenir la part de revenu. Il s’agit des mesures décomposables pondérées par le revenu :

63C’est ainsi que Bourguignon [1979] caractérise le problème de la décomposition en agrégativité et en décomposition additive. Les mesures d’inégalité sont séparées en indicateurs intragroupes et intergroupes. L’agrégativité est moins restrictive car elle est définie sur les contributions des inégalités associées à chaque groupe (Ij). La décomposition additive est plus difficile à obtenir. Elle se base sur la mesure intragroupe (Iw). Plus précisément, l’élément intragroupe est défini par une moyenne pondérée des inégalités associées à chaque groupe (Ij).
Autour de la notion d’additivité
64L’additivité introduite par Bourguignon [1979] requiert des propriétés axiomatiques restrictives, dont seul le coefficient de Theil respecte les conditions. Shorrocks [1980, 1984, 1988] va néanmoins démontrer que le coefficient de Theil n’est pas l’unique mesure.
La décomposition additive reconsidérée, Shorrocks [1984]
65L’hypothèse de décomposition additive s’exprime par :

67où Ij représente l’indice d’inégalité associé au groupe j, wj le poids attaché à l’indicateur Ij et Ib la mesure intergroupe.
68Shorrocks montre que cette propriété de décomposition ne peut être pleinement satisfaite que si les mesures d’inégalité appartiennent à la classe des mesures issues de la famille de l’entropie généralisée que Shorrocks sera lui-même amené à définir par la suite.
69Cette notion de décomposition additive va se révéler insatisfaisante car la somme des poids n’est pas toujours égale à l’unité.
70Ainsi, pour les rares cas où la somme des poids est unitaire, l’indice intragroupe 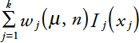

71Cela va conduire Shorrocks [1984] à proposer une version plus faible de l’axiome (DA), en définissant le principe agrégatif :

73où xj est la distribution du groupe j et f une fonction continue en son premier argument. Ce principe agrégatif prévoit notamment la continuité de la fonction f.
74En 1988, Shorrocks incorpore l’idée de cohérence en sous-groupes. Le principe de décomposition cohérente va donc suppléer aux principes précédents.
La décomposition cohérente en sous-groupes (monotonie), Shorrocks [1988]
75Une mesure d’inégalité vérifiant la décomposition cohérente s’écrit :

77où 

78Mais cette fois encore cette propriété est réservée à la mesure de l’entropie généralisée. Car même si l’indice de Gini peut s’écrire sous la forme d’une moyenne pondérée des indices associés aux groupes j, il est construit sur trois éléments et n’intègre pas l’additivité. Par ailleurs, il ne respecte pas la propriété de décomposition cohérente en sous-groupes. En effet, les inégalités à l’intérieur d’un groupe peuvent augmenter en générant une baisse de l’inégalité totale. Cowell [1988] remarque à ce sujet que la mesure de Gini, la variance des logarithmes et l’écart moyen relatif sont trois mauvais indicateurs d’inégalité en raison du non-respect de la cohérence en sous-groupes. L’entropie généralisée satisfait donc d’importantes propriétés que les autres indicateurs n’intègrent pas. Cependant, en 1988 Ebert propose un théorème, permettant de doter l’indice de Gini de la propriété de décomposition additive à condition que les distributions ne se chevauchent pas, ce qui représente une avancée fort appréciable mais encore insuffisante pour hisser l’indicateur au même rang que celui de l’entropie généralisée.
79Parmi les différentes formulations envisagées par Shorrocks pour tenter de résoudre le problème de dépendance (path dependence) existant les composantes intra et intergroupes qui découlent de la décomposition additive, aucune ne se révèle pleinement satisfaisante. Il faudra attendre quelques années pour que d’autres techniques de décompositions soient envisagées afin de tenter d’apporter une solution à ce problème récurrent.
Solutions au problème de « path dependence »
80Le problème de path dependence – que l’on peut traduire littéralement par « problème de dépendance de traitement » – fait référence au problème identifié quelques années plus tôt dans la spécification des composantes intra et intergroupes formulées dans le cadre de la décomposition additive proposée par Shorrocks [1980]. Dans cette section, nous évoquons deux méthodes de décompositions intermédiaires qui ont été proposées pour tenter de pallier ce problème.
La décomposition avec des composantes indépendantes
81Pour remédier au problème de dépendance entre les pondérations des composantes d’inégalité intragroupes et intergroupes observé chez Shorrocks [1980], Foster et Shneyerov [2000] vont proposer une méthode de « décomposition avec des composantes indépendantes » qui repose sur deux techniques de calculs différentes pour la détermination des termes d’inégalité intragroupes et intergroupes. En effet, comme l’ont montré Shorrocks [1980] et Anand [1983], il est possible de mesurer les inégalités de revenu d’une population soit à partir de distributions lissées soit à partir de distributions normalisées, les résultats finaux étant équivalents. Afin d’assurer l’indépendance des deux composantes intragroupes et intergroupes, Foster et Shneyerov définissent les inégalités intergroupes comme le niveau d’inégalités observé sur une distribution de revenus lissée, dans laquelle le revenu de chaque individu est remplacé par le revenu représentatif de son groupe. De la même façon les inégalités intragroupes correspondent au niveau d’inégalité estimé à partir d’une distribution normalisée dans laquelle la distribution de chaque sous-groupe est calibrée sur le niveau global de revenu représentatif. La seule contrainte étant que la somme de ces deux termes d’inégalité ainsi calculés doit permettre de retrouver le montant global d’inégalité initialement observé sur la population mère comme le stipule la définition suivante.
La décomposition avec des composantes indépendantes, Foster et Shneyerov [2000]
82Une mesure d’inégalité pouvant être décomposée selon deux composantes indépendantes s’écrit :

84où r(x) est une fonction représentative du revenu noté x.
85Foster et Shneyerov vont plus loin en montrant que les seules fonctions représentatives du revenu, cohérentes avec la décomposition en composantes indépendantes, sont les moyennes d’ordre q, ?q ? ?.
86Cependant cette propriété de décomposition avec des composantes indépendantes n’est valable que pour une famille restreinte d’indicateurs d’inégalité à un paramètre, notée Iq, à laquelle ni l’indice de Gini, ni les indices de l’entropie généralisée [9] n’appartiennent.
87Une solution alternative consiste à appliquer la décomposition de Shapley. L’attrait de cette décomposition repose sur la valeur de Shapley, habituellement utilisée en théorie des jeux. Cette décomposition consiste à allouer les gains (ou surplus) entre les individus membres d’un groupe en fonction de leur contribution à ce groupe. L’adaptation d’un tel concept à l’économie des inégalités va permettre de résoudre le problème de dépendance observé entre les composantes intra et intergroupes. Les deux composantes vont être assimilées à des facteurs et vont être traitées symétriquement de manière à ce qu’une modification de la composante intergroupe puisse être opérée sans affecter la composante intragroupe.
La décomposition de Shapley
88Les travaux de Auvray et Trannoy [1992], Chantreuil-Trannoy [1999, 2013] et Shorrocks [1999, 2013] ont permis de transposer l’application du concept de valeur de Shapley au domaine des inégalités. Pour établir un parallèle entre cette nouvelle méthode de décomposition et la notion de décomposition en sous-groupes, Shorrocks [1999, 2013] assimile les contributions de l’inégalité à l’intérieur de chaque groupe à des facteurs intragroupes indicés par K = {1,…,m} et celles de l’inégalité entre les groupes, à des facteurs intergroupes, indicés par L tel que L ne contient qu’un seul élément.
89Soit 



91Les éléments W’k et B’ représentent les effets marginaux W intragroupes et intergroupes lorsque chacun des facteurs est éliminé en posant 
92Finalement, les contributions des facteurs intragroupes individuels sont définies par :

94De la même façon, il est possible de définir la décomposition de Shapley de l’indice de Gini, telle que la somme des contributions correspond à l’indice de Gini global. Ces contributions représentent l’effet marginal suite à la modification de chacun des facteurs compte tenu de toutes les séquences d’éliminations possibles. Dans le cas particulier de deux facteurs, Shorrocks montre que la décomposition de Shapley permet d’allouer la moitié des gains (du surplus) à chacun des facteurs K et L. Cette propriété ne se généralise cependant pas facilement à un nombre fini de facteurs et nécessite la séparabilité de ces facteurs, ce qui n’est pas le cas pour l’indice de Gini.
95Si la décomposition de Shapley peut sembler attrayante pour découper symétriquement et équitablement la valeur de l’inégalité globale, elle présente néanmoins quelques inconvénients. Au-delà de la formulation parfois complexe des différentes contributions issues de la décomposition, cette méthode est sensible à la façon dont sont traités les autres facteurs. Rien ne garantit en effet que la contribution assignée à un facteur reste identique si le facteur est traité différemment au cours du processus de décomposition. La solution au problème de « path dependence » reste partielle puisque les contributions 

Méthodes de décomposition selon deux composantes
96Dans cette section, nous insistons sur les méthodes qui mettent l’accent sur la composante d’inégalité intragroupe. Nous distinguons les méthodes qui définissent la composante intragroupe comme une composante à part entière (Rao [1969], Okamoto [2009]), des méthodes qui lui associent la notion de chevauchement entre les revenus individuels (Bhattacharya et Mahalanobis [1967] et Pyatt [1976]).
Spécification de la composante intragroupe
La décomposition de Rao [1969] : une approche matricielle
97Rao utilise une approche matricielle afin de montrer que la décomposition de l’indice de Gini s’écrit sous une forme quadratique. Cette expression permet d’identifier deux éléments. Le premier est une moyenne pondérée des indicateurs de concentration à l’intérieur des groupes. Le deuxième est basé sur les différences entre les sous-populations (i.e., les sous-groupes de la population globale) en relation avec les revenus par tête. La décomposition est issue d’un découpage en classes de revenus rangées par ordre croissant dans la population globale. Les revenus sont supposés également distribués à l’intérieur de chacune des classes de revenus. Les notations sont les suivantes :
- pij est la proportion de population du groupe j (?j = 1,…,k) appartenant à la classe de revenus i (?i = 1,…,t) ;
- xij est la proportion de revenu de la classe de revenus i de la sous-population j mesurée sur le revenu total da la population ;
est le rapport par tête de la jème sous-population sur le revenu global.
98Le coefficient de concentration associé à la population totale est donné par :

100Soit p le vecteur (de taille k) des proportions de taille des différents groupes. L’élément pj du vecteur p est donc la taille relative du groupe j par rapport à la population totale :
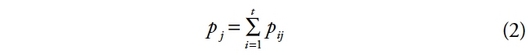
102Soit q le vecteur (de taille k) représentant les proportions de revenu de chaque groupe par rapport à la population mère. L’élément qj du vecteur q s’écrit donc :

104L’indicateur de concentration, mesuré sur la population globale, peut se réécrire sous la forme matricielle suivante :

106L’indice peut ensuite être défini à l’aide de deux autres matrices de même taille k × k. Soit la matrice W composée des indices de concentration à l’intérieur des groupes. Les éléments de cette matrice sont définis par :

108où les coefficients [10] cij peuvent être intégrés dans une matrice carrée [11] C de taille k × k.
109La première ligne de W est composée de l’indicateur intragroupe c11 (et ainsi de suite). La deuxième matrice de taille k × k est notée D. Les éléments de D sont définis tels que :

111La relation qui unit les trois matrices est : C = W + D. L’indice de Gini se reformule par :

113Soit le vecteur b composé des éléments 

115L’équation (11) montre que le coefficient de Gini est décomposé en deux termes. Le premier est une moyenne pondérée des indices de concentration à l’intérieur des groupes. Le second est une forme quadratique en p’ où (bD) est la matrice de la forme quadratique. Chaque paire distincte de sous-populations contribue deux fois à la forme quadratique. Cette dernière est dépendante d’un paramètre d. Ce paramètre mesure les différences entre les classes des distributions j et h. L’appellation « composante intergroupe » n’est donc pas acceptable. En effet, cette expression est réservée aux indices qui reflètent les différences moyennes entre les groupes, alors que cette décomposition procure des inégalités entre les paires de groupes.
116En définitive, la décomposition du coefficient de Gini réalisée par Rao dépend des inégalités à l’intérieur des groupes et des différences entre chaque paire distincte de sous-populations. La relation entre les composantes intra et intergroupes est analysée par Okamoto [2009] au travers d’une nouvelle forme de décomposition basée sur une condition bien spécifique.
La décomposition d’Okamoto [2009] : une approche par le respect de la condition des distributions complètement identiques
117Okamoto fonde sa décomposition sur le respect d’une condition bien spécifique qu’il qualifie de « condition des distributions complétement identiques (CID) ». Cette condition présuppose que l’inégalité intergroupe est nulle si et seulement si la distribution intragroupe de chaque sous-groupe est identique à toutes les autres distributions. [12]
118Cette nouvelle décomposition peut être généralisée à l’indice de distance de Gini ainsi qu’à l’indice de volume de Gini, qui sont deux indices multi-variés introduits par Koshevoy et Mosler [1996]. Pour parvenir à décomposer l’indice de Gini, Okamoto décide d’exprimer cet indicateur comme une différence moyenne relative de Gini (notée R(F)) correspondant au rapport de la différence moyenne de Gini (notée M(F)) sur la moyenne de la distribution, soit :

120où F(y) représente la fonction de répartition de la variable aléatoire non négative Y et où ? désigne sa moyenne.
121Soit une population P partitionnée en k ? {1,…,n} groupes où Fi(y), ?i, et pi sont respectivement la fonction cumulative, la moyenne et la part du groupe i sur l’ensemble de la population. Compte tenu du fait que : 

123On retrouve l’idée selon laquelle l’indice de Gini s’obtient en faisant la somme d’un terme d’inégalité intragroupe et d’un terme d’inégalité intergroupe.
124L’indice de Gini ainsi formulé s’interprète alors comme le total de la variance espérée de la variable binaire (sur diverses valeurs de Y) [13] rapporté à la moyenne.
125Cela permet à Okamoto de reformuler la contribution de chaque groupe au terme d’inégalité intergroupe en faisant apparaître clairement le coefficient de variation de Cramér tel que :

127où c?(Fi, F)(?0) désigne le coefficient de variation de Cramér. [14]
128Il est alors aisé de constater que l’indice de Gini est identique au coefficient de variation de Cramér si chaque unité de la population forme un groupe individuel. Fort de cette constatation, Okamoto établit que le terme d’inégalité intergroupe ne peut être nul que si et seulement si la distribution à l’intérieur de chaque groupe est identique à celle de tous les autres groupes. C’est ce qu’il qualifiera par la suite de « condition des distributions complètement identiques ». Lorsque cette condition est satisfaite la décomposition de l’indice de Gini, au sens où Okamoto l’entend, se résume donc à un seul et unique terme : la composante d’inégalité intragroupe.
Introduction de la notion de chevauchement
La décomposition de Bhattacharya et Mahalanobis [1967] : une approche par la courbe de concentration
129L’objet de leur recherche est de fournir de nouvelles mesures statistiques afin de mesurer les disparités régionales en Inde. Ils s’intéressent notamment aux dépenses de consommation. La courbe de concentration [15] constitue la pierre angulaire de leur décomposition. Ils attirent l’attention sur le fait que cette décomposition n’est pas entièrement satisfaisante car elle s’applique à des distributions qui ne se chevauchent pas. La principale difficulté de la décomposition de l’indice de Gini est de tenir compte du chevauchement entre les distributions. Cette première approche soulève donc un problème fondamental, tout en montrant que la décomposition reste attractive.
130En effet, elle repose sur la relation unissant la courbe de concentration (ici la courbe de Lorenz) au coefficient de Gini (et à la moyenne des différences de Gini ?). [16] Bhattacharya et Mahalanobis ont donc choisi d’utiliser le coefficient ? afin d’exprimer les différentes étapes de leur méthode de décomposition. Ce coefficient ? est désagrégé en indicateurs intragroupes et intergroupes. L’indicateur intergroupe signale le moyen par lequel les inégalités globales de consommation peuvent être réduites si chaque distribution intragroupe est redistribuée de manière égalitaire. L’indice de concentration intergroupe est défini par ?/2?, où ? est la moyenne des différences de Gini entre les groupes :

132où ?i et ?j sont respectivement les moyennes des groupes i et j (?i, j= 1,…,k) avec pi et pj les pourcentages de population détenus par chaque groupe et où k est le nombre de sous-groupes. La moyenne des différences de Gini peut se réécrire en fonction des k groupes :
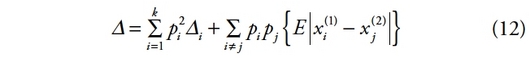
134où 


136Le deuxième terme de l’équation est nul si les distributions ne se chevauchent pas et, dans ce cas, la décomposition comporte deux éléments, au même titre que l’analyse de la variance. Il existe donc une courbe de concentration intergroupe et une courbe de concentration globale. L’aire située entre les deux courbes représente la mesure 
137D’un point de vue historique, cette décomposition figure parmi l’une des premières méthodes de décomposition de l’indice de Gini. On note que cette décomposition soulevait déjà quelques difficultés. L’une de ces difficultés tient notamment au fait que les auteurs comparent la décomposition de l’indice de Gini à l’analyse de la variance qui comprend deux éléments. La décomposition telle qu’elle a pu être présentée précédemment semble cependant offrir trois composantes au lieu de deux.
La décomposition de Pyatt [1976] : une approche matricielle ainsi que par la théorie des jeux
138L’article de Pyatt [1976] marque une rupture dans la littérature. L’expression « coefficient de concentration » est abandonnée pour l’expression « coefficient de Gini ». Le coefficient de Gini peut être interprété comme une valeur espérée, au sens de l’espérance mathématique. Elle est basée sur le fait que chaque individu peut comparer son gain avec celui d’un autre individu qui serait tiré au hasard dans la population. Il est alors possible de fournir une nouvelle décomposition de l’indicateur de Gini basée sur la valeur conditionnelle espérée du jeu. Cette approche est liée à celle de Bhattacharya et Mahalanobis. Elle est, en effet, construite sur les différences absolues de revenu. Soient n revenus notés : x1,…,xn. L’indicateur de Gini faisant intervenir les comparaisons interpersonnelles entre paires d’individus est :

140C’est à partir de cette équation que le jeu va pouvoir être défini. Chaque individu est convié à cette expérience. Un revenu x est tiré au hasard dans la population totale. Si le revenu sélectionné x est supérieur à celui du joueur, alors ce dernier peut choisir x, sinon il peut garder son revenu actuel. Aucun individu ne peut perdre à participer à ce genre de jeu. Toutes les personnes ont une probabilité non négative de gagner, excepté les gens très riches dont la probabilité se rapproche de zéro. Pour chaque individu, le gain est nul (s’il est riche) ou bien il gagne la différence entre x et son revenu. Le gain espéré de l’individu i est donc :

142En mesurant la moyenne des gains espérés individuels (m), on obtient le numérateur de l’indicateur de Gini :

144L’indice de Gini est donc interprété comme la moyenne du gain espéré, si chaque individu a le choix entre être lui-même ou prendre la place d’une autre personne prise au hasard dans la société. En supposant que la population est décomposée en k sous-groupes tels qu’un individu du groupe i se compare aux membres du groupe j tirés au hasard, il est possible de montrer que l’indicateur de Gini se réécrit sous la forme matricielle suivante :

146où p est le vecteur colonne (de taille k) des proportions de population, ? est le vecteur colonne (de taille k) où le kième élément est la moyenne du groupe k et E est la matrice (k ×?k) où eij = E(gain / i ? j) telle que l’expression E(gain / i ? j) représente la moyenne des gains espérés des individus appartenant au groupe i qui se comparent aux membres de j.
147On remarque que (?’p)?1 est le dénominateur de l’indice de Gini (équation (12)) : la moyenne des revenus de la population mère. Le deuxième terme p’E p représente le numérateur de G (le terme m) : la moyenne des gains espérés individuels.
148Soit E* la matrice E normalisée telle que :

150où la matrice 
151L’indicateur de Gini mesuré sur la population globale peut alors se réécrire :

153avec 
154Ainsi, en considérant un cas particulier où il n’existerait pas d’inégalité intragroupe, Pyatt montre que E se réécrit :

156où la matrice A est une matrice (k ×?k) dont les éléments au-dessus de la diagonale sont nuls et les autres égaux à un. Les inégalités intergroupes peuvent alors être définies à l’aide des différences entre les moyennes des sous-groupes, ce qui revient à écrire que :

158où E1 est une matrice symétrique (k × k) d’éléments e1ij = min{eij,eji}. La matrice des gains espérés est donc séparée endeux composantes dont l’une (

160Par conséquent G devient :

162où 
163L’équation (21) correspond à la désagrégation finale du coefficient de Gini. Cette décomposition comporte deux éléments et trois informations fondamentales. Les éléments sur la diagonale de 
164Cette décomposition est proche de celle de Bhattacharya et Mahalanobis [1967] dans le sens où les inégalités de chevauchement sont incluses dans la partie des inégalités intragroupes. Cette décomposition est légitime car les inégalités de chevauchement (les différences de revenu entre les groupes issues du chevauchement entre les distributions) sont dépendantes des inégalités intragroupes. En effet, plus le chevauchement augmente et plus les inégalités intragroupes sont faibles. Néanmoins, il est possible de séparer, comme l’a fait Rao, [18] l’indice de Gini en deux composantes, sans faire intervenir les inégalités intergroupes (les différences moyennes entre les groupes).
165Ces premières méthodes de décomposition bien qu’étant toutes basées sur des concepts différents sont intrinsèquement liées les unes aux autres. Elles vont notamment susciter de nombreuses critiques auxquelles leurs auteurs ne pourront faire face et devront être abandonnées au profit d’idées plus novatrices qui sont exposées dans les lignes qui suivent.
Méthodes de décomposition selon trois composantes
166La décomposition de l’indice de Gini peut également se présenter sous la forme de trois composantes. La spécification d’une troisième composante a nécessité la contribution de plusieurs travaux de recherche et s’est vue attribuer différentes interprétations. Dans cette section, nous marquons une distinction entre les méthodes visant à définir la troisième composante comme un terme résiduel difficile d’interprétation et les méthodes visant à associer cette troisième composante à la notion de chevauchements entre distributions.
Introduction d’un terme résiduel
La décomposition de Mookherjee et Shorrocks [1982] : une approche par le rejet de la troisième composante issue du chevauchement entre les distributions
167On considère une population mère composée de n individus (ou ménages). On note ? la moyenne des revenus de cette population. Soit xi le revenu du ième individu (?i = 1,…, n). On suppose que la population est divisée en k sous-populations de taille nh et de moyenne ?h (?h = 1, …, k). Nh désigne l’ensemble des revenus du groupe h. L’indicateur de Gini est :

169Les différences de revenu peuvent être regroupées afin de mettre en évidence les différences de revenu entre individus appartenant aux mêmes groupes et entre individus appartenant à des groupes différents :

171On constate que l’indice est décomposé en deux parties. La première représente les inégalités issues des différences entre les revenus des mêmes groupes. La deuxième est constituée des différences de revenu entre individus appartenant à des groupes différents. Le premier terme incorpore les différences binaires issues de chaque groupe. Elles représentent le numérateur des indicateurs de Gini de chaque groupe. Pour faire apparaître complètement ces indices, il est nécessaire d’introduire le dénominateur : 

173où vh est la proportion d’individus appartenant au groupe h telle que vh = nh / n, ?h est la proportion de revenu détenue par le groupe h avec ?h = ?h / ? et où R dépend de l’intensité avec laquelle les distributions se chevauchent, appelé « terme d’interaction ».
174Les auteurs ne spécifient pas le terme d’interaction. Il s’obtient simplement par différence :

176Lorsque les revenus sont également distribués à l’intérieur de chaque groupe, l’indicateur de Gini s’exprime sous la forme suivante :

178Ce cas particulier élimine les inégalités à l’intérieur des groupes. Les auteurs prennent l’exemple des tranches d’âge. Cela signifie qu’il n’existe pas d’inégalité entre les individus d’une même classe d’âge. Une parfaite égalité des revenus prévaut dans chaque groupe. Les chevauchements entre les distributions sont donc inexistants (R = 0). L’inégalité totale est ainsi expliquée par les inégalités intergroupes : les différences entre les revenus moyens des classes d’âge. En revanche, la décomposition du coefficient de Gini (24) reste particulière. Le terme R est impossible à interpréter avec précision. Il s’agit simplement du terme qui permet de maintenir l’exactitude de la décomposition. De plus, elle répond difficilement aux changements temporels. Considérons une augmentation des inégalités intragroupes sans changement du nombre d’individus et de la moyenne de chaque classe. On s’attend donc à une augmentation de l’indice G. Le terme d’interaction peut néanmoins absorber cette variation afin que G diminue.
179Selon les auteurs, cette décomposition s’inscrit dans la lignée des travaux de Bhattacharya et Mahalanobis, Rao et Pyatt. Il s’agit en effet d’un mélange de ces décompositions. Rappelons que les décompositions de Bhattacharya et Mahalanobis [1967] et de Pyatt [1976] sont identiques dans le sens où elles spécifient l’indice intergroupe, alors que celle de Rao spécifie l’indice intragroupe. On remarque que Mookherjee et Shorrocks parviennent à préciser les fondements intragroupes et intergroupes de la décomposition. Par conséquent, il s’agit d’une synthèse des décompositions précédentes. Cette approche n’offre cependant pas de spécification du terme d’interaction. Ce dernier trouva néanmoins une définition intéressante au cours des années qui suivirent.
La décomposition de Lambert et Aronson [1993] : une approche par les courbes de Lorenz
180Lambert et Aronson se sont focalisés sur les travaux de Mookherjee et Shorrocks [1982], pour établir une nouvelle décomposition de la mesure de Gini. Ils s’intéressent surtout à ce que Mookherjee et Shorrocks nomment « terme d’interaction », ou « terme résiduel ».
181En partant d’une simple approche géométrique basée sur la courbe de Lorenz, les auteurs spécifient les trois composantes de la décomposition où Gw est la composante d’inégalité intragroupe, GB est la composante d’inégalité intergroupe et R est le terme résiduel (qui est égal à zéro si les distributions ne se chevauchent pas).
182La population mère est composée de n individus dont les revenus sont notés : x1, x2,…, xn. Cette population comprend k groupes. La moyenne de la population est ?. La moyenne et la taille de chaque groupe sont respectivement ?j et nj (?j = 1,…, k). La courbe de Lorenz est définie par L(P). L’ordonnée L(P) est la part des revenus cumulés de la population globale détenue par chaque classe. La variable en abscisse P est la proportion de population totale de chaque classe. Le coefficient de Gini se formule :

184Les termes P – L(P) définissent les segments situés entre la première bissectrice du carré de côtés unitaires et la courbe de Lorenz. Par conséquent, l’opération qui consiste à multiplier par deux la somme des segments entre 0 et 1 donne bien le coefficient de Gini : deux fois l’aire contenue entre la courbe de Lorenz et la bissectrice. A partir de la courbe de Lorenz, les étapes de la décomposition de l’indicateur de Gini sont les suivantes.
185– La contribution des inégalités intergroupes. On considère que les revenus sont également distribués à l’intérieur de chaque groupe. Les individus possèdent la moyenne de leur sous-groupe correspondant. Les moyennes sont classées de manière à ce que le groupe 1 possède la plus faible moyenne, et ainsi de suite : ?1 ? ?2 ? … ? ?k. La courbe de Lorenz intergroupe LB est donc construiteen imaginant que les individus du groupe jpossèdent un revenu égal à ?j, pour tous les j = 1,…, k. La composante d’inégalité intergroupe s’obtient alors en faisant la somme des segments entre LB(P) et la bissectrice de telle sorte que :

187– La contribution des inégalités intragroupes. Ces inégalités sont calculées de la même manière que l’inégalité globale. Les revenus des individus sont classés par ordre croissant. La proportion de population totale des individus du groupe j est ensuite liée à leur proportion de revenu pour obtenir la courbe de concentration intragroupe C(P). En d’autres termes, il s’agit de calculer l’aire entre les courbes LB(P) et C(P), soit :

189– Les chevauchements entre les distributions de revenu des différents groupes. Les individus sont classés par groupe. De cette façon, le plus pauvre du groupe 2 peut se situer au-dessus d’un individu plus riche mais se situant dans le groupe 1 (où la moyenne est plus faible). Il faut donc reclasser les individus, comme le classement de la population mère pour éviter ces chevauchements. De cette manière, on obtient la procédure suivante : P ? LB(P) ? C(P) ? L(P). Cette dernière étape permet de déduire la composante de chevauchements entre les distributions notée R :

191L’ajout de ces trois composantes, permet alors de retrouver l’indice de Gini mesuré sur la population globale, [19] en effet :
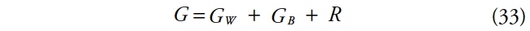
193Le terme R doit être positif. Il révèle l’intensité avec laquelle il faut permuter les individus pour atteindre la troisième étape. Il est à la fois un terme intragroupe et un terme intergroupe. Il est un phénomène intergroupe à cause de son interprétation en termes de chevauchements entre les groupes. Mais il est aussi un élément intragroupe car les chevauchements sont issus des inégalités intragroupes. Il est donc possible de nommer le terme R conformément à l’appellation de Mishra et Parikh [1991] : les inégalités « à travers les groupes ». Cette définition diffère quelque peu de celle proposée par Nygard et Sandström en 1981, selon laquelle la « composante à travers les groupes » correspondait à la somme GB + R. Le terme « inégalités intergroupes » est réservé à l’entropie généralisée (aux mesures additivement décomposables).
194Les recherches de Lambert et Aronson défendent le coefficient de Gini et sa troisième composante. Le terme d’interaction n’est donc pas impossible à interpréter comme le font remarquer Mookherjee et Shorrocks [1982]. Lambert et Aronson dotent l’indicateur d’une information statistique essentielle et réconcilient la décomposition de l’indicateur de Gini avec les travaux de Bhattacharya et Mahalanobis [1967], puisque ces derniers montraient l’impossibilité d’unir les inégalités intragroupes avec une courbe de concentration intragroupe.
195Le problème de la spécification de cette troisième composante n’est cependant pas résolu. Une incertitude plane encore quant à sa véritable nature. Les recherches vont donc se poursuivre et il faudra attendre 1997 pour que les choses se précisent avec la publication de nouveaux travaux que nous allons exposer dans le paragraphe suivant.
Spécification du terme résiduel comme composante de transvariation
La décomposition de Lerman et Yitzhaki [1991] : une approche par la spécification de la troisième composante comme indice de stratification
196Les sociologues se consacrent plus à l’étude de la stratification qu’à celle des inégalités de revenu. La stratification fait appel à la notion de strates ou de couches horizontales qui regroupent une ou plusieurs caractéristiques de la population globale. Selon cette définition, un indice mesurant la stratification doit capter le degré de chevauchement entre plusieurs distributions. Il existe donc un lien étroit entre les inégalités intergroupes et la notion de stratification entre les groupes. De même, l’augmentation des inégalités d’un groupe pauvre (par augmentation des hauts revenus) peut augmenter la stratification. D’autre part, une augmentation des inégalités des populations riches (par diminution des bas revenus) peut aussi accroître la stratification. Les décompositions qui lient les éléments intragroupes et intergroupes possèdent donc des éléments qui peuvent expliquer ce phénomène. Les mesures décomposables issues de l’entropie ne sont pas de bons candidats pour cette mesure. En effet, les mesures intergroupes basées sur les différences entre les moyennes des groupes ne fournissent pas ce genre d’explication. A contrario, l’indice de Gini est la mesure adéquate.
197La première étape de cette décomposition consiste à définir un indice de stratification qui sera noté Stel que :

199où xij est le revenu de l’individu i appartenant au groupe j et Fj(xij) la fonction de répartition du groupe qui mesure le rang de l’individu i (du groupe j) dans la sous-population j : Fj(xij) = rang (xij)/nj. Les individus non issus du groupe j sont notés « non j ». La fonction de répartition qui leur est associée est définie par : F-j(xij) = rang (xij)/(n - nj).
200Le numérateur de cet indicateur exprime la covariance entre la variable revenu et la différence entre le rang de l’individu dans son propre groupe et celui qu’il aurait eu dans le reste de la population. Le dénominateur est un facteur de normalisation. Ce qui permet d’établir que l’indicateur de stratification est compris dans l’intervalle [-1 ;1].
201Afin de relier la notion de stratification à la notion de chevauchement les auteurs proposent un indicateur de chevauchement qu’ils notent O et qu’ils formulent de la façon suivante :

203où pj est la proportion de la population appartenant au groupe j : pj = nj/n et R est le rang des individus dans la population globale avec rj le rang dans la population j. [20] Cet indicateur est ensuite repris et étudié en détails par Yitzhaki [1994]. [21]
204Afin d’établir un lien avec la décomposition de l’indice de Gini, Lerman et Yitzhaki [1984] ont introduit la formule du coefficient de Gini basée sur l’opérateur de covariance :

206où ? est la moyenne des revenus de la population globale. On note Gj l’indice de Gini mesuré sur le groupe j. Soit 


208La première composante est l’inégalité intragroupe : la moyenne pondérée des indices de Gini à l’intérieur des groupes. La deuxième composante est l’inégalité intergroupe. La troisième est l’impact de la stratification. L’indicateur de Gini global équivaut à deux fois la covariance entre le revenu de l’individu et son rang dans la population globale, divisé par la moyenne des revenus. Si les groupes deviennent des observations, l’indicateur intergroupe est défini de manière similaire. Il s’agit de deux fois la covariance entre la moyenne des revenus de chaque groupe et la moyenne des rangs, divisé par la moyenne totale des revenus. La lecture de la littérature montre cependant que cet indice de Gini intergroupe est totalement différent de ceux introduits dans les approches précédentes. Ces dernières sont basées sur la moyenne de chaque sous-population. Autrement dit, si tous les groupes ont la même moyenne, l’indice intergroupe est nul. Dans la présente décomposition, la mesure d’inégalité intergroupe de Gini est nulle si et seulement si les groupes ont le même rang moyen. Il est donc possible d’avoir une composante intergroupe nulle, alors que les moyennes sont différentes. Dans ce même cas, l’indice intergroupe de Gini défini par Pyatt [1976] est positif. Dans l’approche de Lerman et Yitzhaki, les groupes sont égaux en termes de position moyenne à l’intérieur de la distribution. De ce fait, l’indice de Gini intergroupe peut revêtir une valeur négative. Supposons par exemple que la population soit constituée de deux groupes. Le groupe pauvre comprend uniquement des faibles revenus et un seul individu extrêmement riche. Le rang moyen du groupe pauvre (dans la population totale) peut être inférieur à celui du groupe riche alors que la moyenne est plus élevée.
209L’élément de stratification permet de proposer une décomposition dotée d’une troisième composante totalement définie. D’ailleurs, les auteurs critiquent l’approche de Mookherjee et Shorrocks [1982] selon laquelle le dernier élément est un terme d’interaction dépourvu de toute signification économique. La troisième composante est ici clairement définie car une augmentation de la stratification exerce un effet négatif sur les inégalités. En effet, une forte stratification implique une faible variabilité de rang. La faible variabilité de rang implique à son tour un faible niveau d’inégalité. D’où la relation opposée qui les unit.
La décomposition de Silber [1989] : une nouvelle approche matricielle
210En 1989, Silber formule une nouvelle approche matricielle qui s’inscrit dans la continuité de celle antérieurement proposée par Pyatt [1976], afin de décomposer l’indice de Gini. Il montre tout d’abord qu’à partir de données individuelles, l’indicateur s’exprime par :

212où e’ est un vecteur ligne dont les éléments sont égaux à (1/n), où s est un vecteur colonne dont les éléments (classés par ordre décroissant) sont les parts de revenu total détenues par chaque individu et où G* est une matrice (n?n). La diagonale principale de G* est constituée de 0. Les éléments sous la diagonale sont égaux à 1 et les éléments au-dessus de la diagonale sont égaux à –1. Les individus sont répartis en sous-groupes. L’indice de Gini intergroupe est alors défini par :

214où f’ est le vecteur ligne des proportions de population globale de chaque classe de revenu et s le vecteur colonne des proportions de revenu de chaque classe. Les vecteurs f et s sont ordonnés par rapport au classement décroissant des ratios sj/fj (où j = 1,…, k est le sous-indice représentant les différents groupes). La contribution à l’inégalité totale des inégalités qui s’exercent à l’intérieur des groupes est définie par :

216L’indice de Gini Gjj mesuré sur les revenus du groupe j est :

218où e’ et sij sont respectivement les vecteurs de proportions des individus du groupe j (dans la population totale) et la proportion de revenu de chaque individu du groupe j. La décomposition de l’indicateur de Gini de Silber [1989] est donc :

220où GO est le terme résiduel mesurant l’intensité de chevauchement entre les distributions. Cette intensité de chevauchement sera ensuite reprise et spécifiée par Dagum [1997a, 1997b] avec les travaux de Gini lui-même [1916], comme nous le précisons ci-après.
La décomposition de Dagum [1997a, 1997b] : une approche par la spécification des trois composantes en cohésion avec les travaux précurseurs de Gini, la transvariation
221Une population mère P, où prévalent n unités de revenu xi (i = 1, …, n), est partitionnée en k sous-populations Pj (j = 1, …, k) où Pj est de taille nj, de fonction de répartition Fj(x) et de moyenne ?j. On note F(x) et ?, respectivement, la fonction de répartition et la moyenne mesurées sur P. Afin de faire apparaître les revenus des k sous-populations, le vecteur de revenus sur P s’écrit :

223A partir du vecteur des revenus, le coefficient de Gini mesuré sur P est donné par :

225L’indice de Gini associé à la sous-population Pj est :

227La différence moyenne des revenus ?jh est une généralisation de la différence moyenne de Gini (nommée aussi GMD). Elle représente la moyenne des différences de revenu des nj × nh combinaisons binaires des individus appartenant à Pj et Ph :

229Elle mesure la différence de revenu espérée entre un individu tiré au hasard de la sous-population j et un individu tiré au hasard de la sous-population h. On retrouve ainsi un des aspects essentiels des travaux de Pyatt [1976] en rapport avec la théorie des jeux et le gain espéré que chaque individu peut gagner. ?jh permet de calculer le coefficient de Gini entre deux groupes (Gjh, Dagum [1987]) s’exprimant sous la forme :

231Lorsque les groupes Pj et Ph sont de même taille et distribués de manière identique, l’indice de Gini mesuré entre deux groupes est égal à l’indice de Gini intragroupe mesuré sur Pj ou Ph :

233Remarquons aussi que les indicateurs associés à deux groupes sont symétriques :

235La différence moyenne de Gini ?jh mesurée entre les sous-populations Pj et Ph peut se réécrire à partir de deux concepts.
236Le premier est la distance directionnelle brute djh. Il s’agit d’une moyenne pondérée des différences de revenus xji – xhr pour chaque revenu xji d’un membre de Pj supérieur au revenu xhr d’un membre de Ph, étant donné qu’en moyenne le groupe Pj est plus riche que le groupe Ph. La distance directionnelle brute se formule de la manière suivante :

238Le deuxième concept est le moment d’ordre 1 de transvariation p entre la jème et la hème sous-population avec ?j > ?h. Il s’agit de la moyenne pondérée des différences de revenus xhr – xji pour chaque revenu xhr d’un membre de Ph plus important que le revenu xji d’un membre de Pj. L’expression transvariation (Gini [1916], Dagum [1959, 1960, 1961]) désigne les différences de revenus qui sont de signe opposé à celui de la différence des moyennes des sous-groupes correspondants. Elle est donnée par :

240Ces deux concepts sont liés par la relation suivante :

242On démontre que lorsque deux distributions ne se chevauchent pas, le moment d’ordre 1 de transvariation est nul : pjh = 0 ? djh = ?jh. Aussi, lorsque la distance économique brute est égale au moment d’ordre 1 de transvariation les moyennes des deux distributions sont égales : pjh = djh = ½ ?jh ? ?j = ?h.
243Dagum [1997a, 1997b] conclut d’après les résultats précédents que :

245La distance économique brute et le moment d’ordre 1 de transvariation permettent de définir la richesse économique nette entre les sous-populations Pj et Ph : djh – pjh??j > ?h. Etant donné que djh – pjh admet 0 comme origine et ?jh comme maximum, on peut normaliser la richesse économique nette, qui devient ainsi la richesse économique relative ou encore distance économique directionnelle. [22]
246La richesse économique relative Djh (ou distance économique directionnelle) entre les sous-populations Pj et Ph est le ratio entre la richesse économique nette et son maximum ?jh :
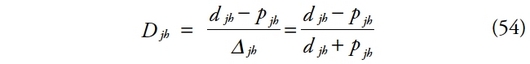
248Djh est inclus dans l’intervalle fermé [0,1]. Il est un nombre sans dimension car djh, pjh et ?jh ont la dimension du revenu. La richesse économique relative sépare les inégalités intergroupes en deux composantes :
- la contribution nette des inégalités de revenu entre les souspopulations Pj? et Ph, obtenue par le produit Gjh × Djh ;
- et la contribution des intensités de transvariations entre Pj et Ph, obtenue par Gjh ×?(1–Djh). L’addition de ces deux produits mesure de manière brute les inégalités de revenu entre deux sous-populations Pj et Ph.
249La décomposition du coefficient de Gini, proposée par Dagum [1997a, 1997b] est séparable en trois éléments. Ce sont des contributions distinctes de l’inégalité globale mesurée sur la population mère P. Dagum [1997a] montre que l’indice de Gini total calculé sur P s’écrit :
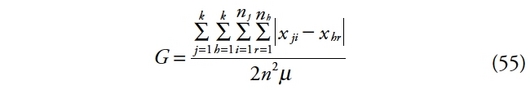
251Cette expression fait apparaître les différences de revenu intragroupes et intergroupes. Les caractéristiques des sous-groupes sont très importantes. Elles sont décisives quant à l’évaluation de la contribution de chaque groupe à l’inégalité totale. Ces spécificités sont notamment le pourcentage d’individus appartenant au groupe Pj(pj) et le pourcentage de revenus de Pj lié au revenu global de la population P (sj) :

253D’après ces pondérations, l’indice de Gini calculé sur P devient :

255Dans cette équation, ? est une matrice symétrique (k × k) où les éléments sont les indices de Gini entre l’ensemble des paires de sous-populations Pj et Ph (Gjh). Les éléments de ? situés sur la diagonale principale sont les indices de Gini associés aux groupes Pj (Gjj, ?j = 1,…, k). Les vecteurs p et s sont les proportions de population et de revenu des k sous-populations (dont les éléments sont respectivement les pj et sj). En développant l’équation, on met en évidence, les termes de la matrice ? :
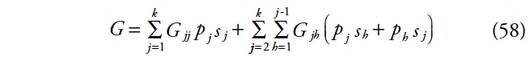
257Deux sommes apparaissent. La première indique la contribution des inégalités à l’intérieur des k sous-groupes. La deuxième composante, la double somme, est la contribution des inégalités entre les 

259Comparées aux inégalités moyennes entre les groupes, les inégalités intergroupes brutes offrent davantage d’informations puisqu’elles mettent en évidence les différences de revenus entre chaque paire de groupes. En multipliant la contribution des inégalités intergroupes par Djh puis par 1-Djh (soit au total par 1), nous pouvons distinguer les inégalités intergroupes nettes [Gnb] des inégalités intergroupes de transvariation [Gt] :
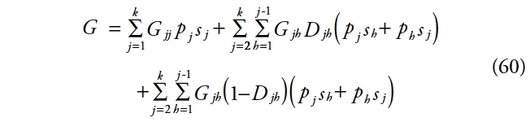
261La contribution des inégalités de revenu inhérentes à l’intensité de la transvariation,

263mesure le poids des inégalités intergroupes issues du chevauchement entre les distributions. Il s’agit d’inégalités particulières. Le chevauchement signifie que certains individus de la distribution la plus pauvre possèdent des revenus supérieurs aux personnes de la distribution la plus riche. L’intensité de la transvariation permet de capter les inégalités générées par les hauts revenus des souspopulations les plus pauvres. A contrario, les disparités provenant des revenus élevés des sous-populations riches sont données par la contribution nette des inégalités intergroupes à l’inégalité totale :

265Il s’agit des inégalités entre les k sous-populations dont les revenus sont issus de la partie de non-chevauchement entre les distributions. Il s’agit aussi des inégalités moyennes entre les groupes puisque ?j = ?h (?j,h = 1, …, k) ? Gnb = 0. Le dernier élément de la décomposition est la contribution des inégalités intragroupes à l’inégalité totale :
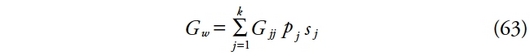
267Il s’agit d’une simple moyenne pondérée des indicateurs de Gini associés aux groupes Pj.
268Les trois contributions de l’inégalité globale permettent d’introduire l’équation fondamentale de la décomposition de l’indicateur de Gini, [23]

270où : Gw est la contribution des inégalités à l’intérieur des sous-populations ; Gnb est la contribution nette des inégalités entre les sous-populations ; et Gt l’inégalité inhérente à l’intensité de transvariation entre les sous-populations.
271Les inégalités sont donc partagées en contributions intragroupes et intergroupes. La partie intergroupe est conditionnée par le comportement des distributions. Pour des distributions de même moyenne, la composante intergroupe est uniquement constituée des transvariations intergroupes :
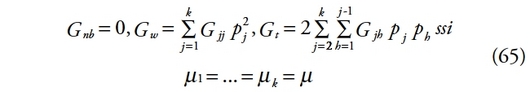
273Si les distributions sont indépendantes et identiquement distribuées (i.i.d.), on a :
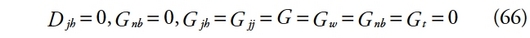
275En revanche, si les k distributions ne se chevauchent pas alors les distances économiques entre chaque groupe sont égales à l’unité :

277En définitive, la décomposition du coefficient de Gini permet de prendre connaissance des groupes générateurs d’inégalité et de savoir dans quelles mesures ils s’éloignent des autres sous-populations dans le souci d’atteindre une répartition plus égalitaire des revenus, préalable nécessaire à la redistribution entre les groupes.
278Cette dernière décomposition permet notamment de résoudre le problème soulevé plusieurs années auparavant concernant la nature de cette troisième composante, longtemps considérée à tort comme un simple résidu.
Quelques généralisations
279La littérature sur les décompositions en sous-groupes des mesures d’inégalité compte deux généralisations majeures. A partir des années 2000, s’affiche la volonté d’axiomatiser le concept de comparaisons interpersonnelles de revenus présent dans les travaux de Rao [1969], Pyatt [1976], Mookherjee et Shorrocks [1982] ou encore Dagum [1997]. Cette axiomatisation est finalement fournie par Ebert [2010] sous le nom de décomposition faible et permet de mettre l’accent sur la composante d’inégalité intergroupe. Dans le même temps, le concept de décomposition en sous-groupes est étendu à celui de décomposition sur plusieurs niveaux de partitions, chacune de ces partitions étant subdivisée en différents sous-groupes imbriqués.
Généralisation du concept de comparaisons interpersonnelles
280Les enjeux de l’axiomatisation du concept de comparaisons interpersonnelles (par paires) des revenus individuels sont multiples. Ils sont de plus intrinsèquement liés à la définition de la composante d’inégalité intergroupe. Car si la décomposition additive se révèle utile pour les analyses empiriques, elle est parfois considérée comme une propriété forte. Dagum [1997] met en avant le fait que la décomposition additive suppose que la composante intergroupe est basée sur le revenu représentatif des agents situés dans les différents groupes. Une telle spécification entraîne la perte d’informations relatives à la variance ainsi qu’à l’asymétrie des distributions. Les distributions de revenus s’écartent en effet significativement de la normalité. Il s’agit donc de définir un concept de décomposition plus faible qui permette, non plus de définir la composante intergroupe en fonction de la moyenne des revenus des individus des différents groupes, mais en tenant compte des comparaisons interpersonnelles de revenus opérées entre paires d’individus. Les prémices de cette propriété étaient déjà présents dans les travaux de Rao [1969], Pyatt [1976], Mookherjee et Shorrocks [1982] ou encore Dagum [1997]. Ils seront complétés par la suite par les travaux de Kolm [1999] et Mussard et Terraza [2009] qui ont développé et étudié les mesures d’inégalité basées sur des paires afin de capturer l’envie entre chacune des paires d’individus. Ces travaux ne reposent cependant pas sur une démarche axiomatique.
281La contribution d’Ebert [2010] permet d’introduire un nouvel axiome, qualifié d’axiome de décomposition faible par opposition à l’axiome de décomposition additive, considéré comme fort. La définition proposée par Ebert, suppose que la population est scindée en deux sous-groupes, de manière à faire apparaître deux composantes : une composante intragroupe dont la formulation correspond à celle employée par Shorrocks [1980] et une composante intergroupe captant l’ensemble des comparaisons par paires de revenus individuels.
La décomposition faible en sous-groupes, Ebert [2010]
282Une mesure d’inégalité faiblement décomposable s’écrit pour tout n = (n1 + n2) avec n1 ? 1 et n2 ? 1 :

284où ?1(n), ?2(n), ?(n) sont des fonctions de pondérations strictement croissantes telles que n (n1,n2) est le vecteur des tailles des sous-groupes de la population. Le vecteur de revenus du groupe 1 (2) est noté x1 (x2) tel que 

285Cette dernière propriété se révèle parfaitement adaptée à la structure de l’indice de Gini et permet de caractériser une nouvelle classe de mesures suggérée quelques années auparavant par Chameni [2006a, 2006b]. Cette nouvelle classe de mesures, désormais qualifiée de ?-Gini, réunit à la fois l’indicateur de Gini (cas où ? = 1) mais également le coefficient de variation au carré (lorsque ? = 2) qui appartient à la famille des mesures dérivées de l’entropie généralisée introduite par Shorrocks. Les deux familles de mesures sont ainsi réunies autour d’une seule et même propriété de décomposition. Le lien entre ces deux familles d’indicateurs va même être approfondi par certains auteurs, jusqu’à proposer une adaptation de la décomposition de Dagum en sous-groupes aux mesures de type ?-Gini.
L’?-décomposition en sous-groupes de Chameni [2011] : une adaptation de la décomposition en sous-groupes de Dagum
286Les récents écrits concernant l’indice de Gini ont permis de révéler cet indicateur comme une mesure faiblement décomposable. Cette notion de décomposabilité faible (DÊC(?)) résulte des recherches successives menées par divers auteurs et relève de la notion de comparaisons interpersonnelles (par paires) de revenus précédemment évoquée.
287En 2006, Chameni suggère un nouvel indicateur d’inégalité dont la structure de base est construite à partir de l’indice de Gini auquel est intégré un paramètre ? d’aversion pour l’inégalité (cf. équation (68)). L’introduction de ce paramètre ? s’inscrit dans la continuité des travaux de Theil [1967], Atkinson [1970] ou encore Yitzhaki [1983, 1984] qui ont cherché à doter leur mesure d’inégalité d’un paramètre de sensibilité. Cette sensibilité encore appelée degré d’aversion pour l’inégalité a pu revêtir diverses formes. Chez Theil le degré d’aversion à l’inégalité est introduit conformément à la théorie de l’information, noté ?, il intervient à la fois au dénominateur de la mesure d’inégalité ainsi que sous forme d’exposant. Chez Yitzhaki on le retrouve sous la notation ? où il fait office de coefficient multiplicatif mais également d’exposant alors que chez Atkinson il intervient uniquement en tant qu’exposant mais toujours à deux reprises car il s’agit d’une moyenne généralisée et est noté ?.
288La principale difficulté est alors de savoir où précisément appliquer cet exposant. Mais le choix d’Ebert semble justifié par des valeurs particulières empruntées par le coefficient d’aversion pour l’inégalité. On constate en effet que pour une valeur de ? égale à l’unité, on retrouve l’indice de Gini [1921]. Par ailleurs, pour une valeur de ? égale à 2, l’indice obtenu correspond au coefficient de variation élevé au carré. C’est donc le degré d’aversion pour l’inégalité qui va déterminer la mesure d’inégalité la plus appropriée pour évaluer les disparités présentes au sein d’une distribution.
289Chameni [2011] propose alors une extension de la décomposition en sous-groupes de l’indice de Gini de Dagum pour les mesures de type ?-Gini. Les composantes de cette décomposition se déduisent directement de celles établies par Dagum [1997a, 1997b], en adoptant la formulation générale suivante :
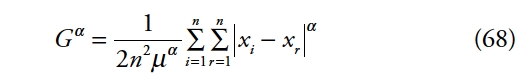
291La décomposition qui s’opère sur une population P pouvant être partitionnée en k sous-groupes homogènes se présente donc de la façon suivante :

293
294Lorsque ? vaut 1, cette décomposition est identique en tout point à la décomposition de Dagum. L’intérêt de cette décomposition va donc se manifester pour des valeurs de ? strictement supérieures à l’unité. Par exemple, lorsque ? vaut 2 cette décomposition s’applique au coefficient de variation au carré qui est un indicateur généralement assimilé à la famille de l’entropie généralisée définie par Shorrocks. Il est important de noter que pour toute valeur de ? strictement supérieure à 1, les composantes de la décomposition ne sont plus comprises entre 0 et 1 (y compris le ?-Gini total).
295Les différentes méthodes de décomposition en sous-groupes mentionnées jusqu’à présent ne font référence qu’à un seul niveau de partition. Ces diverses approches n’en sont pas moins généralisables à un nombre fini de partitions. Parmi les méthodes remarquables, nous avons choisi d’évoquer les généralisations de décompositions sur plusieurs niveaux de groupes se rapportant aux indicateurs de l’entropie généralisée et à l’indice de Gini (sous sa forme standard ou pour des extensions de sa formulation).
Généralisation du concept de sous-groupes à plusieurs niveaux de partition
La décomposition en multi-niveaux de l’indice de Theil
296En 1985 la décomposition en sous-groupes prend une nouvelle dimension et est étendue à plusieurs niveaux de partitions issus d’une même population mère. Cette généralisation des méthodes de décomposition en sous-groupes est adaptée pour la première fois par Cowell [1985] à un indice de la famille de l’entropie généralisée et porte le nom de décomposition en multi-niveaux.
297L’indice de Theil est, en effet, le premier indicateur d’inégalité pour lequel une décomposition en multi-niveaux fut envisagée. En 1984, Adelman et Levy décident d’étendre les travaux de Fishlow [1972] et arrivent à la conclusion que la décomposition en multi-niveaux de l’indice de Theil est à utiliser avec précaution car « elle peut induire en erreur ». En 1985, Cowell reprend les écrits d’Adelman et Levy et démontre la simplicité d’application et d’interprétation d’une telle méthode de décomposition.
298Soient I, J, K trois partitions conçues à partir de la population mère, où K se rapporte au niveau de formation acquis par les individus, J concerne leur lieu de naissance et I fait référence au groupe ethnique auquel ils appartiennent – conformément aux données d’Aldelman et Levy [1984]. Il est cependant possible de croiser certains de ces critères comme par exemple le niveau de formation avec la nativité, ce qui revient à former une nouvelle partition notée KJ.
299Soient Xijk et Yijk le nombre d’individus à l’intérieur de chaque groupe et le revenu agrégé par les sous-groupes i,j,k. Les parts de chaque groupe vont être définies par :

301L’indice de Theil est noté T lorsqu’il s’agit de la mesure globale d’inégalité, Ti pour la mesure intragroupe du groupe 
302La décomposition de cet indicateur sur les divers niveaux de partitions retenue par Cowell revêt la forme suivante :

304Cowell montre alors que l’équation (72) peut alternativement s’écrire :
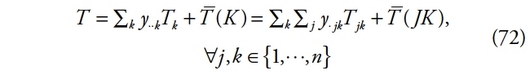
306Sur une population donnée les équations (72) et (73) ont toutes la même valeur. De plus, elles rapportent toutes les informations nécessaires à la mise en œuvre de la décomposition en multi-niveaux.
307Une condition sine qua non au bon déroulement d’une décomposition en multi-niveaux est que chaque individu de la population ne doit appartenir qu’à un seul et unique ensemble de partitions. Par ailleurs, dans le cas particulier où les partitions construites à partir de la population mère sont orthogonales il est possible de faire certaines simplifications. En effet, l’orthogonalité au sens où Cowell l’entend signifie que : 
308A l’issue de la décomposition en multi-niveaux (comme pour toute autre méthode de décomposition) la somme de chacune des composantes précédemment formulées doit permettre de retrouver le montant des inégalités globales qui avaient pu être observé avant le processus de décomposition. Cowell insiste notamment sur la simplicité d’interprétation des divers résultats. Et, contrairement à ce que semblaient avancer Adelman et Levy [1984], l’ampleur de l’inégalité globale n’est en aucune façon sensible à l’ordre dans lequel les partitions sont choisies pour la pratique de la décomposition. L’indice de Theil est bien décomposable en multi-niveaux sans qu’il n’y ait de quelconque risque d’erreur.
La décomposition en multi-niveaux des mesures de l’entropie généralisée
309Salas [2002] s’intéressait à un problème de convergence interterritoriale, qui faisait déjà l’objet de nombreuses publications. Les études menées sur le sujet - encouragées par les développements survenus dans le domaine de la théorie économique des modèles de croissance - permirent d’établir la convergence comme moyen de validation d’un modèle économique. Les méthodes jusqu’alors utilisées pour tester l’existence de la convergence régionale sont les mesures de ?-convergence et ?-convergence proposées par Barro et Sala-i-Martin [1990,1992]. [24] Cependant, il se trouve que ces mesures de convergence ne respectent pas certaines propriétés axiomatiques exigibles d’une bonne mesure d’évaluation des inégalités telles que l’anonymat et la S-convexité. [25]
310Afin de résoudre le problème de convergence interterritoriale, Salas décide de généraliser la propriété de décomposition en multi-niveaux, mise en avant par Cowell [1985] pour l’indice de Theil, à l’ensemble des mesures de la famille de l’entropie généralisée (y compris la mesure de Theil-0 séparable en pondérations de population). Salas suggère ainsi l’utilisation de mesures d’inégalités relatives S-convexes. En effet, les mesures de l’entropie généralisée sont connues pour respecter l’ensemble des propriétés axiomatiques présentées en introduction, y compris la S-convexité mentionnée précédemment. Salas formalise donc ce qu’il appelle la « décomposition additive en multi-niveaux des inégalités » qui vaut pour toutes les mesures de la classe de l’entropie généralisée.
311Soit une population mère P sur laquelle est formée une partition contenant k sous-groupes. Une sous-partition est définie à partir de la partition telle que chaque sous-groupe de la sous-partition S est un sous-ensemble de groupes dans la partition. Ainsi, le nombre de groupes dans K ne peut pas être plus grand que le nombre de groupes dans S soit : K ? S. Soit I (x1, …, x2) un indicateur global d’inégalité de la famille de l’entropie généralisée alors :
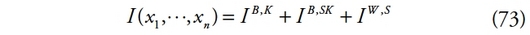
313où IB,K est le terme d’inégalité intergroupe de premier ordre calculé le long de la première partition. IB,SK est un terme d’inégalité intergroupe de second ordre calculé le long de la seconde partition elle-même située à l’intérieur de la première partition. Il est important de noter que l’ensemble des composantes intergroupes des sous-groupes mutuellement exclusifs est généré comme la somme de termes d’inégalité de 1er et 2nd ordre indépendamment de l’ordre suivi dans la séquence de décomposition. Enfin IW,S est une composante d’inégalité intragroupe estimée pour les groupes de la seconde partition S.
314Salas porte une attention particulière à la composante IB,SK qui se calcule comme une somme pondérée des inégalités intergroupes. Le schéma de pondération va être identique à celui de la composante intragroupe :
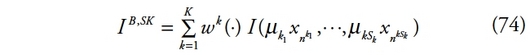
316où nks, ?kS, Sk sont respectivement la taille de la population, la moyenne des revenus et le nombre de sous-groupes s à l’intérieur du groupe k ; 
317Il existe une relation de complémentarité entre les différentes composantes, de telle sorte que lorsque la composante d’inégalité intragroupe diminue d’un certain montant, la composante intergroupe augmente exactement du même montant. Ainsi, la composante d’inégalité intergroupe convergera vers l’inégalité totale chaque fois que le nombre de groupes tendra vers le nombre d’individus. A contrario, si le nombre de groupes tend vers 1, la composante d’inégalité intergroupe va tendre vers 0.
318Un raisonnement contraire tient pour la composante intragroupe.
319Par ailleurs, il est possible de généraliser cette décomposition additive en multi-niveaux en considérant non plus deux partitions mais une séquence finie de sous-partitions et de partitions classées en fonction du nombre de sous-groupes qu’elles contiennent de telle sorte que :
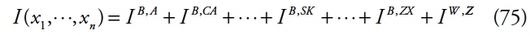
321avec : A ?C ? ??? ? K ? S ??? ? X ? Z
322Toutes les implications de cette propriété de décomposition additive en multi-niveaux permettent d’évaluer avec davantage de précision l’implication de chacun des groupes dans les inégalités (ou la convergence) observées.
323Les recherches sur les capacités de l’indice de Gini à être décomposé en sous-groupes vont progressivement être élargies à plusieurs niveaux de partitions – au même titre que l’entropie généralisée. Notons que des travaux antérieurs à ceux que nous nous apprêtons à présenter ont cependant été réalisés. [26]
La décomposition en multi-niveaux de l’indice de Gini
324Parmi toutes les méthodes de décomposition en sous-groupes évoquées antérieurement, nombreuses sont celles qui ont été remises en cause et dont l’application n’est de ce fait, pas recommandée. La décomposition en multi-niveaux de l’indice de Gini commence donc par le choix de la bonne méthode de décomposition en sous-groupes qui permettra d’atteindre le résultat souhaité. Mais ce choix va être facilité par le fait qu’en 2005, seule la décomposition de Dagum [1997a ; 1997b] arrive à passer au travers des diverses critiques qui lui sont adressées.
325La décision de Mussard, Pi Alperin, Seyte et Terraza [2006] d’étendre cette décomposition en sous-groupes sur plusieurs niveaux de groupes imbriqués, semble donc justifiée. Le cadre de départ est alors identique à celui retenu par Salas [2002] et considère une population P d’où sont issues une première partition K et une seconde sous-partition S située à l’intérieur de la précédente. Chacune de ces partitions contient respectivement un nombre k et s de sous-groupes tels que K ? S.
326Soient nz, ?z (respectivement, nw, ?w) le nombre d’individus et le revenu moyen du zième sous-groupe (respectivement wième sous-groupe) de la seconde sous-partition. L’indice de Gini se décompose alors selon les trois composantes suivantes :
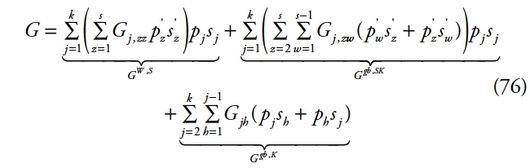
328où : 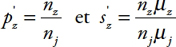


330L’indicateur de Gini total s’obtient en faisant la somme de la contribution des inégalités observées le long de la seconde partition S à l’intérieur de K (GW,S avec la contribution brute des inégalités entre les sous-partitions de la partition S à l’intérieur de la partition K (Ggb,SK) ainsi que la contribution brute des inégalités intergroupes le long de la première partition K (Ggb,K). Il s’agit bien là d’une extension directe de la décomposition proposée par Dagum comme l’ont montré Mussard et al [2006]. Par ailleurs, les auteurs démontrent également que cette décomposition en multi-niveaux formulée dans le cas de deux partitions peut être généralisée à un nombre fini de partitions.
331Une extension directe de la décomposition de Mussard et al [2006] peut être proposée pour les indicateurs de type ?– Gini.
La décomposition en multi-niveaux du ?-Gini
332Compte tenu de ce qui a été dit précédemment la généralisation de la décomposition du ?-Gini sur plusieurs niveaux de partition est immédiate. Dans le cas de deux niveaux partition S et K tels que K ? S, la décomposition se formule de la manière suivante :
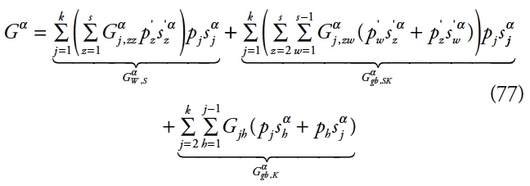
334Pour un degré d’aversion à l’inégalité unitaire cette décomposition est strictement identique à la décomposition en multi-niveaux initialement proposée par Mussard et al [2006].
335Ces généralisations à plusieurs niveaux de partitions ouvrent la voie à de plus larges horizons de recherche et vont progressivement conduire les chercheurs à envisager des méthodes de décomposition qui pourront être adaptées à des distributions multi-dimensionnelles.
336Dix méthodes de décomposition en sous-groupes élaborées pour l’indice de Gini (ou des extensions de cet indice) viennent ainsi d’être répertoriées et synthétisées. Toutes ces décompositions sont différentes et pourtant elles convergent toutes vers un même résultat : l’indicateur d’inégalité global de Gini. La décomposition en multi-niveaux – quel que soit l’indicateur d’inégalité auquel elle s’applique – permet d’enrichir la compréhension des inégalités d’une dimension supplémentaire en offrant la possibilité aux analystes d’envisager de multiples combinaisons entre les divers critères sociaux de partitionnement retenus pour l’étude des disparités. Cependant, cette propriété de décomposition est ambivalente et doit être utilisée avec précaution. Un nombre de groupes important (pour une population de taille suffisante) assure certes une meilleure précision des calculs des inégalités réalisés sur les diverses partitions, cependant leur interprétation sera plus complexe. Il sera alors difficile de déterminer avec exactitude la cause principale de ces inégalités.
337On a longtemps pensé que l’indice de Gini n’était pas une mesure décomposable. En effet, les indicateurs étaient jusque-là tous décomposables en deux termes. De plus, il était difficile de comprendre le rôle joué par le troisième élément (Gt). Celui-ci a été comparé à un résidu ou un terme d’interaction (voir Mookherjee et Shorrocks [1982]), jusqu’aux travaux de Silber [1989], Deutsch et Silber [1997] et Dagum [1997a, 1997b]. En particulier, en 1997, ils ont été les premiers (dans la même revue) à démontrer, de manière différente, que le troisième élément est issu d’un concept introduit par Gini [1916] et repris par Dagum [1959, 1960, 1961] : la transvariation. Il s’agit d’un changement radical dans le domaine de la décomposition de l’indicateur de Gini. En effet, ces travaux ont permis de réconcilier l’indice de Gini avec une méthode de décomposition (en deux ou trois éléments) dont chaque contribution est un élément clair et défini de l’inégalité totale, spécifié en cohésion avec les travaux précurseurs de Gini.
338Les premières limites ont été soulevées par Shorrocks [1980, 1984] avec la notion de cohérence en sous-groupes (voir aussi Shorrocks [1988] et Cowell [1988]). Les critiques de Shorrocks et Cowell s’appuient sur le fait que leur mesure (la classe de l’entropie généralisée) satisfait la décomposition additive et la cohérence en sous-groupes. Adelman et Levy [1986, 1984] tentent de démontrer à Cowell [1985] que la mesure de Theil ne satisfait pas une décomposition non ambiguë. Même si d’un point de vue mathématique celle-ci est correcte, la mesure de Theil peut conduire à des mauvaises estimations lorsqu’on s’intéresse aux facteurs ou aux sources des revenus individuels.
339Les récentes recherches réalisées par Ebert [2010] permettent de montrer que l’indice de Gini est une mesure faiblement décomposable pour laquelle chacune des composantes (intragroupes ou intergroupes) est construite sur la base de fonctions de pondérations croissantes qui en aucun cas ne reposent sur les moyennes des distributions. Ebert introduit également un principe de transfert bien spécifique que toutes les mesures faiblement décomposables satisfont : le principe de concentration. Ce principe est plus faible que le principe de transfert de Pigou-Dalton puisqu’il concerne l’ensemble des individus appartenant à la population mère. Les transferts qui en découlent seront plus ou moins redistributifs selon les valeurs qui seront empruntées par la moyenne des revenus et un paramètre k compris dans l’intervalle [0 ;1] et fixé de manière exogène.
340Finalement, l’analyse des disparités de revenus au sein d’une population nécessite une étude attentive des caractéristiques propres aux individus qui la composent. Mais qu’il soit question d’un ou de plusieurs sous-groupes imbriqués ou non dans des partitions, l’indice de Gini est décomposable cela ne fait, désormais, plus aucun doute.
Références
- I. Adelman et A. Levy [1984] : Decomposing Theil’s Income of Income Inequality into Between and Within Components : A Note, Review of Income and Wealth, 30, pp. 119-121.
- I. Adelman et A. Levy [1986] : Decomposing Theil’s Index of Income Inequality : A Reply, Review of Income and Wealth, 32, pp. 107-108.
- S. Anand [1983] : Inequality and Poverty in Malaysia, Oxford University Press, Londres.
- A. Atkinson [1970] : On the Measurement of Inequality, Journal of Economic Theory, 55, pp. 244-263.
- C. Auvray et A. Trannoy A. [1992] : Décomposition par source de l’inégalité des revenus à l’aide de la valeur de Shapley, Journées de micro-économies appliquées, Sfax.
- L. Baringhaus et C. Franz [2004] : On a New Multivariate Two-Sample Test, J. Multivar. Anal, 8, pp. 190-206.
- N. Bhattacharya et B. Mahalanobis [1967] : Regional Disparities in Household Consumption in India, Journal of the American Statistical Association, 62, pp. 143-161.
- F. Bourguignon [1979] : Decomposable Inequality Measures, Econometrica, 47, pp. 901-920.
- S-R. Chakravarty et B. Dutta [1987] : A Note on Measures of Distance Between Income Distributions, Journal of Economic Theory, 41, pp. 185-188.
- C. Chameni Nembua [2006] : A note on the Decomposition of the Coefficient of Variation Squared : Comparing Entropy and Dagum’s Methods, Economics Bulletin, 4(8), pp. 1-8.
- C. Chameni Nembua [2011] : A Generalization of the Gini Coefficient : Measuring Economic Inequality, mimeo.
- G. Champernowne [1952] : The Graduation of Income Distribution, Econometrica, 20(4), pp. 591-615.
- F. Chantreuil et A. Trannoy [1999] : Inequality Decomposition Values : The Trade-off between Marginality and Consistency, working paper # 9924, THEMA, université de Cergy-Pontoise.
- F. Chantreuil et A. Trannoy [2013] : Inequality Decomposition Values : The Tradeoff between Marginality and Efficiency, Journal of Economic Inequality, 11(1), pp. 83-98.
- F-A. Cowell [1980a] : Generalized Entropy and the Measurement of Distributional Change, European Economics Review, 13(1), pp. 147-159.
- F-A. Cowell [1980b] : On the Structure of Additive Inequality Measures, Review of Economics Studies, 47(3), pp. 521-531.
- F-A. Cowell [1985] : Multilevel Decomposition of Theil’s Index on Inequality, Review of Income Wealth, 31(2), pp. 201-205.
- F-A. Cowell [1988] : Inequality Decomposition : Three Bad Measures, Bulletin of Economic Research, 40(4), pp. 309-312.
- F-A. Cowell [2000] : Measurement of Inequality, in Atkinson A. et Bourguignon F. (ed.), Handbook of Income Distribution, 1, pp. 87-166.
- C. Dagum [1959] : Transvariazione fra più di due distribuzioni, in Gini, C.(ed.) Memorie di metodologia statistica, vol. II, Libreria Goliardica, Roma.
- C. Dagum [1960] : Teoria de la transvariacion, sus aplicaciones a la economia, Metron, vol. XX, pp. 1-206.
- C. Dagum [1961] : Transvariacion en la hipotesis de variables aleatorias normales multidimensionales, Proceedings of the International Statistical Institute, vol. 38, Book 4, Tokyo, pp. 473-486.
- C. Dagum [1977] : A New Model of Personal Income Distribution : Specification and Estimation, Economie appliquée, vol. XXX n° 3, pp. 413-436.
- C. Dagum [1980] : Inequality Measures Between Income Distributions with Applications, Econometrica, 48(7), pp. 1791-1803.
- C. Dagum [1987] : Measuring the Economic Affluence between Populations of Income Receivers, Journal of Business and Economic Statistics, 5(1), pp. 5-12.
- C. Dagum [1996] : Quelques réflexions sur les fondements micro de la macroéconomique et les fondements macro de la microéconomique, lecture académique donnée en l’occasion de la remise du grade de docteur honoris causa par l’université de Montpellier 1, France, université Montpellier 1 : pp. 11-18.
- C. Dagum [1997a] : A New Approach to the Decomposition of the Gini Income Inequality Ratio, Empirical Economics, 22(4), pp. 515-531.
- C. Dagum [1997b] : Decomposition and Interpretation of Gini and the Generalized Entropy Inequality Measures, Proceedings of the American Statistical Association, Business and Economic Statistics Section, 157th Meeting, pp. 200-205.
- C. Dagum [1998] : Fondements de bien-être social et décomposition des mesures d’inégalité dans la répartition du revenu, Economie appliquée, tome L1 n°4, pp. 151-202.
- C. Dagum [1999] : Linking the Functional and Personal Distributions of Income, in
- Silber J. (ed.), Handbook of Income Inequality Measurement, Kluwer Academic Publishers, pp. 101-132.
- H. Dalton [1920] : The Measurement of Inequality of Incomes, Economic Journal, 30, pp. 348-361.
- T. Das et H. Parikh [1982] : Decomposition of Inequality Measures and a Comparative Analysis, Empirical Economics, 7(1), pp. 23-48.
- J. Deutsch et J. Silber [1997] : Gini’s ‘Transvariazione’ and the Measurement of Distance Between Distributions, Empirical Economics, 22(4), pp. 547-554.
- J. Deutsch et J. Silber [1999] : Inequality Decomposition by Population Subgroups and the Analysis of Interdistributional Inequality, in Silber J. (ed.), Handbook of Income Inequality Measurement, Kluwer Academic Publishers, pp. 163-186.
- U. Ebert [1984] : Measures of Distance Between Income Distributions, Journal of Economic Theory, 32(2), pp. 266-274.
- U. Ebert [1988] : On the Decomposition of Inequality : Partitions into Nonoverlapping Subgroups, in Eichorn W. (ed.), Measurement In Economics. New-York : Physica Verlag, pp. 399-412.
- U. Ebert [2010] : The Decomposition of Inequality Reconsidered : Weakly Decomposable Measures, Mathematical Social Sciences, 60(2), pp. 94-103.
- J-M. Esteban [2000] : Un anàlisis de la polarizaciòn de la renta provincial en España, 1955-1993, Moneda y Credito.
- A. Fishlow [1972] : Brazilian Size Distribution of Income, American Economic Review, 62, pp. 381-402.
- J-E. Foster, J. Greer et E. Thorbecke [1984] : Notes and Comments. A Class of Decomposable Poverty Measures, Econometrica, 52, pp. 761-766.
- J-E. Foster et A-A. Schneyerov [2000] : Path Independent Inequality Measures, Journal of Economic Theory, 91(2), pp. 199-222.
- C. Gini [1912] : Variabilità e Mutabilità, éd. E. Pizetti & T. Salvemini, reprinted in Memorie di metodologica statistica, Rome, Libreria Eredi Virgilio Veschi, 1955.
- C. Gini [1916] : Il concetto di transvariazione e le sue prime applicazioni, Giornale degli Economisti e Rivista di Statistica, dans Gini C. (ed.) (1959), pp. 21-44.
- C. Gini [1921] : Measurement of Inequality of Incomes, The Economic Journal, pp. 124-126.
- G-H. Hardy, J-E. Littlewood et G. Polyà [1934] : Inequalities, Cambridge University Press.
- S-C. Kolm [1966] : The Optimal Production of Social Justice, colloques internationaux du CNRS, Biarritz, 2-9 septembre.
- G-A. Koshevoy et K. Mosler [1996] : The Lorenz Zonoid of a Multivariate Distribution, Journal of the American Statistical Association, 91(434), pp. 873-882.
- P-J. Lambert et R-J. Aronson [1993] : Inequality Decomposition Analysis and the Gini Coefficient Revisited, The Economic Journal, 103, pp. 1221-1227.
- R. Lerman et S. Yitzhaki [1984] : A Note on the Calculation and Interpretation of the Gini Index, Economics Letters, 15(3), pp. 363-368.
- R. Lerman et S. Yitzhaki [1991] : Income Stratification and Income Inequality, Review of Income and Wealth, 37(3), pp. 313-329.
- M-O. Lorenz [1905] : Methods for Measuring Concentration of Wealth, Journal of the American Statistical Association, 9(70), pp. 209-219.
- M. Mangahas [1975] : Income Inequality in the Philippines : A Decomposition Analysis, World Employement Programme working paper, n°12, Genève, Office international du travail.
- B. Milanovic et S. Yitzhaki [2002] : Decomposing World Income Distribution : Does the World Have a Middle Class ?, Review of Income and Wealth, 48(2), pp. 155-178.
- V. Mishra et A. Parikh [1991] : Houshold Consummer Expenditure Inequalites in India : a Decomposition, Economics discussion paper n° 9111, University of East Anglia.
- D. Mookherjee et A. Shorrocks [1982] : A Decomposition Analysis of the Trend in UK Income Inequality, The Economic Journal, 92(368), pp. 886-902.
- S. Mussard [2004] : Décompositions multidimensionnelles du rapport moyen de Gini : applications aux revenus italiens de 1989 et 2000, Thèse de doctorat, université Montpellier 1.
- S. Mussard, M-N. Pi Alperin, F. Seyte et M. Terraza [2006] : Extensions of Dagum’s Gini Decomposition, Statistica & Applicazioni, vol. IV, special issue n°2, pp. 5-30.
- S. Mussard et M. Terraza [2009] : La décomposition du coefficient de Gini et des mesures dérivées de l’entropie : les enseignements d’une comparaison, Recherches économiques de Louvain, 75(2), pp. 151-181.
- F. Nygard et A. Sandström [1981] : Measuring Income Inequality, Stockholm : Almqvist et Wicksell.
- M. Okamoto [2009] : Decomposition of Gini and Multivariate Gini Indices, The Journal of Economic Inequality, 7(2), pp. 153-177.
- V. Pareto [1896] : Ecrits sur la courbe de la répartition de la richesse, œuvres complètes de Vilfredo Pareto publiées sous la dir. de Giovanni Busino, Genève : Librairie Droz, 1965.
- G. Pyatt [1976] : On the Interpretation and Disaggregation of Gini Coefficients, Economic Journal, 86, pp. 243-255.
- G. Pyatt, C-N. Chen et J. Fei [1980] : The Distribution of Income by Factor Component, Quarterly Journal of Economics, 95(3), pp. 451-473.
- V-M. Rao [1969] : Two Decompositions of Concentration Ratio, Journal of the Royal Statistical Society, séries A 132, pp. 418-425.
- X. Sala-i-Martin [1996] : The Classical Approach to Convergence Analysis, The Economic Journal, 106, pp. 1019-1036.
- R. Salas [2002] : Multilevel Interterritorial Convergence and Additive Multidimensional Inequality Decomposition, Social Choice and Welfare, 19(1), pp. 207-218.
- I. Schur [1923] : Über eine Klasse von Mittlebildungen mit Anwendungen auf der Determinantentheorie, Sitzungsber, Berliner Mat. Ges., 22, pp. 9-29.
- A-K. Sen [1973] : On Economic Inequality, Clarendon Press, Oxford.
- A-F. Shorrocks [1980] : The Class of Additively Decomposable Inequality Measures, Econometrica, 48(3), pp. 613-625.
- A-F. Shorrocks [1982] : On the Distance Between Income Distributions, Econometrica, 50(5), pp. 1337-1339.
- A-F. Shorrocks [1984] : Inequality Decomposition by Population Subgroups, Econometrica, 52(6), pp. 1369-1386.
- A-F. Shorrocks [1988] : Aggregation Issues in Inequality Measurement, Physica-Verlag,
- W. Heichhorn, Measurement in Economics, New York, pp. 429-452.
- A-F. Shorrocks [1999] : Decomposition Procedures for Distributional Analysis : A Unified Framework Based on the Shapley Value, Tech. rep., mimeo.
- A-F. Shorrocks [2013] : Decomposition Procedures for Distributional Analysis : A Unified Framework Based on the Shapley Value, Journal of Economic Inequality, 11(1), pp. 99-126.
- J. Silber [1989] : Factor Components, Population Subgroups and the Computation of the Gini Index of Inequality, Review of Economics and Statistics, 71(1), pp. 107-115.
- S-K. Singh et G-S. Maddala [1976] : A Function for Size Distribution of Income, Econometrica, 25(4), pp. 568-590.
- L. Soltow [1960] : The Distribution of Income Related to Changes in the Distribution of Education, Age and Occupation, Review of Economics and Statistics, 42(4), pp. 450-453.
- H. Theil [1967] : Economics and Information Theory, North-Holland Publishing Company, Amsterdam.
- Q. Wodon [1999] : Between Group Inequality and Targeted Transfers, Review of Income Wealth, 41(1), pp. 21-40.
- S. Yitzhaki [1983] : On an Extension of the Gini Inequality Index, International Economic Review, 24(3), pp. 617-628.
- S. Yitzhaki [1994] : Economic Distance and Overlapping of Distributions, Journal of Econometrics, 61(1), pp. 147-159.