La décision de crédit
Procédure et comparaison de la performance de quatre modèles de prévision d'insolvabilité
Pages 177 à 183
Citer cet article
- GADHOUM, Yoser,
- GUEYIE, Jean-Pierre
- et KARIM SIALA, Mohamed,
- Gadhoum, Yoser.,
- et al.
- Gadhoum, Y.,
- Gueyie, J.-P.
- et Karim Siala, M.
https://doi.org/10.3917/rsg.224.0177
Citer cet article
- Gadhoum, Y.,
- Gueyie, J.-P.
- et Karim Siala, M.
- Gadhoum, Yoser.,
- et al.
- GADHOUM, Yoser,
- GUEYIE, Jean-Pierre
- et KARIM SIALA, Mohamed,
https://doi.org/10.3917/rsg.224.0177
Notes
-
[1]
Bankruptcydata. com (http://www.bankruptcydata.com).
-
[2]
La décision de crédit est fondamentale pour toute institution financière. Aussi, Barrickman (2003) souligne-t-il l’importance et la nécessité pour chaque banque de bien définir, clarifier et spécifier dans un document écrit tous les règlements et toutes les politiques internes en matière de crédit. Ces règlements et politiques constituent un plan stratégique pour le département de crédit. Il devrait être élaboré par le Conseil d’administration ou, à défaut, par la haute direction de la banque, en collaboration avec le département de crédit.
-
[3]
Voir Cohen, Gilmoure et Singer (1966), Altman (1980) et Bartlett (2000) pour d’autres illustrations du processus de crédit).
-
[4]
Nous supposons ici que le client va vers le prêteur. Bien que ce soit souvent le cas, il est à noter que dans un environnement concurrentiel, où plusieurs institutions se bousculent pour faire des offres au client, cette étape est généralement précédée par une sollicitation de ce dernier. Cette sollicitation peut prendre plusieurs formes : appels téléphoniques, courriers postaux, courriers électroniques, etc. Le but ultime est d’emmener le client à pencher pour les services offerts par le solliciteur.
-
[5]
Une autre catégorie de modèles utilisant les données de marché recourt aux écarts de taux d’intérêt entre les obligations corporatives et des obligations gouvernementales ayant les mêmes caractéristiques pour déduire la probabilité implicite de défaut d’un émetteur.
-
[6]
Pour les détails de ces résultats, voir les tableaux 3 à 6 qui figurent en annexe.
1 Pendant la décennie quatre-vingt-dix, et au cours de la récession du début des années 2000, les défaillances d’entreprises, mesurées par le nombre d’ouvertures de procédures de redressement et de liquidation judiciaire par les tribunaux de commerce, ont connu une envolée spectaculaire. En France par exemple, après un pic historique en 1993 où elles ont atteint 68000, ces défaillances se sont établies à 61000 en 1997, contre 46500 en 1990. Aux États-Unis, en 2001, 257 entreprises publiques ayant des actifs totalisant 256 milliards de $ se sont placées sous le chapitre 11 de la loi sur les faillites, chiffre le plus élevé depuis l’année 1980. [1]
2 Une des caractéristiques principales de cette ère est le fait que les défaillances débouchent de plus en plus sur une liquidation, plutôt que sur un redressement ou une cession de l’entreprise. De plus, elles touchent autant les grands groupes cotés en Bourse que les petites et moyennes entreprises.
3 Pour les établissements financiers, cette évolution s’est traduite par une augmentation non négligeable du risque de crédit. Quant aux entreprises industrielles et commerciales, qui sont souvent, sans en avoir toujours pleinement conscience, le premier banquier de leurs clients au travers des délais de paiement qu’elles leur accordent, cet accroissement du nombre des faillites a pu avoir des conséquences plus dramatiques : le non-paiement d’une importante facture par un client défaillant est en effet susceptible de remettre en cause la survie de l’entreprise qui en est victime. Elle peut même enclencher une véritable réaction en chaîne. Le risque d’insolvabilité constitue donc pour ces entreprises un péril financier majeur, au même titre que le risque de change pesant sur les entreprises actives à l’exportation.
4 Se prémunir contre les risques liés à l’insolvabilité des débiteurs est donc devenu un impératif pour tous les prêteurs, qu’ils soient établissement financier, entreprise industrielle ou société commerciale. Cette généralisation des pratiques et du risque de crédit rend nécessaire une bonne compréhension du processus de crédit, ainsi qu’une connaissance des modèles d’évaluation du risque de crédit. C’est à cette tâche de vulgarisation que s’attelle cet article qui par ailleurs analyse la performance relative de quatre modèles de prévision d’insolvabilité.
5 Le texte continue comme suit : La section 2 traite de la décision de crédit. Dans un premier temps, nous décrivons les différentes étapes du processus d’analyse de crédit, en prenant soin de mettre en évidence les facteurs qui entrent en jeu lors de l’évaluation des demandes de crédit présentées par les clients. Dans un second temps, nous faisons une revue des modèles d’évaluation du risque de crédit les plus couramment utilisés au cours des vingt dernières années. La section 3 présente les données et la méthodologie servant à tester la performance de quatre modèles de prévision de l’insolvabilité. Il s’agit de l’analyse discriminante, du partitionnement récursif, de l’algorithme génétique et des réseaux de neurones artificiels. La section 4 présente et discute les résultats desdits tests, et la section 5 sert de conclusion à l’article.
1. La décision de crédit
1.1. Le processus d’analyse du crédit
6 Le processus d’analyse du crédit comprend plusieurs phases, dont la plus importante en terme de quantification du risque du client est l’analyse de son dossier de crédit. [2] De façon générale, les principales étapes dans la décision de crédit peuvent se résumer comme suit [3] :
- application pour le prêt ;
- évaluation du risque de crédit et décision d’accorder ou de refuser le prêt ;
- structuration du prêt, vérifications, signature du contrat de prêt et déboursé ;
- suivi de la performance des paiements.
8 Dans la phase d’application pour le prêt, le client présente au prêteur une demande de prêt conforme aux spécifications de ce dernier. Cette demande contient généralement tous les renseignements pertinents à l’analyse du dossier et à la prise de décision. [4] Dans le cas contraire, ils devront être fournis.
9 L’évaluation du risque de crédit (ou risque de défaut de paiement) représente l’étape cruciale de la gestion du crédit. D’elle dépend en grande partie la performance du prêt consenti au client. Il s’agit pour le prêteur de déterminer le plus adéquatement possible le risque réel de l’emprunteur afin de prendre la décision appropriée d’acceptation ou de refus du prêt, et, en cas d’acceptation, de proposer au client une juste tarification des services offerts. À ce stade, l’accent est généralement mis sur les cinq « C » de l’analyse du crédit que sont : la Capacité (financière) de remboursement de l’emprunteur ; le Caractère, qui a trait à sa valeur morale et à son intention de rembourser ; le Capital, qui reflète sa solidité financière ; le Collatéral, qui fait référence aux garanties que ce dernier peut offrir et les Conditions du marché, représentées par la conjoncture économique générale et sectorielle, et en particulier par le niveau des taux d’intérêt. C’est donc dire que se limiter à l’analyse des états financiers de l’emprunteur c’est ne faire qu’une partie de l’analyse de la demande de crédit.
10 Les données nécessaires à l’analyse de la situation financière du client proviendront principalement des états financiers, des agences de notation du crédit et de différentes sources externes. Les questionnaires de cueillette d’informations seront un outil privilégié pour les prêts aux particuliers. On y recueille des informations telles que le nombre d’années passées à l’adresse actuelle, le nombre d’années d’occupation du présent emploi, le nombre de personnes à charge, la rémunération actuelle, les charges et autres engagements financiers, etc. Des informations sur le dossier actuel ou passé de crédit du client, telles que les soldes des comptes et les habitudes de paiement seront utiles. Tant pour le crédit aux particuliers que pour le crédit corporatif, un plan d’affaires et des états financiers pro-forma fourniront des renseignements sur les perspectives futures. Toutes ces informations sont utilisées dans des analyses et/ou modèles de notation « credit scoring » pour déterminer la qualité de la demande de crédit considérée.
11 Le processus d’évaluation d’une demande de crédit corporatif est plus complexe. Il comprendra de façon générale une analyse de l’économie afin d’en déceler les tendances des années futures ; une analyse de l’industrie dans laquelle opère l’entreprise emprunteuse (cycles dans l’industrie, changement dans la compétition, innovation technologique…) et de sa position concurrentielle dans cette industrie ; une analyse du facteur humain dans l’entreprise et de la qualité de la gestion ; une analyse de la situation financière de l’entreprise et, s’il y a lieu, une analyse de son risque environnemental.
12 L’évaluation du risque du client (individuel ou corporatif) se termine par la décision d’accorder ou de refuser le crédit. L’étape de la structuration du prêt suit, lorsque la décision est favorable. Les termes du prêt comprennent entre autres les composantes suivantes : le montant définitif du prêt, l’échéance, le taux d’intérêt et l’échéancier des remboursements ; les frais de gestion (si applicables) ; les garanties exigées (si nécessaires) et les restrictions imposées au client (Catanach, Kemp et Pettit, 2000 ; Morsman, 2002).
13 Le taux d’intérêt exigé est fixé par le banquier à la lumière de l’évaluation du risque de crédit de l’entreprise. Plus il est grand, plus grand devrait être le taux d’intérêt exigé. Toutefois, lors de cette étape, l’analyste devrait aussi prendre en considération toutes les caractéristiques spéciales de chaque relation d’affaires comme l’ancienneté du client, son historique des prêts avec la banque, l’industrie dans laquelle il évolue, sa taille, etc. Les garanties (exemple : hypothèque d’une résidence ou d’une immobilisation) sont quant à elles exigées pour les prêts qui dépassent un certain montant et sont plus présentes pour les prêts à long terme. En plus d’exiger ces garanties, les banques pourraient se protéger contre d’éventuelles détresses financières en imposant à leurs clients des restrictions dans le contrat de prêt, qui devraient être respectées tout au long de la durée de celui-ci. Quelques exemples de ces conditions pourraient être : ne pas contacter de nouvelles dettes à long terme sans l’avis du prêteur ; ne pas accepter d’éventuelles offres de fusions ou d’acquisitions ; maintenir un certain niveau de fonds de roulement, ne pas augmenter le niveau du dividende pendant la durée du prêt, fournir au prêteur des états financiers trimestriels et le rapport annuel durant toute la durée du prêt ; etc. Une vérification d’usage permet de confirmer la validité de toute la documentation versée au dossier et des informations fournies par le client. Lorsque tout est correct le contrat de prêt est signé, et le montant définitif du prêt déboursé par la banque.
14 La dernière étape du processus d’analyse de crédit consiste à assurer un suivi de la performance du prêt et d’intervenir au besoin, en cas de dégradation de la qualité de celui-ci.
1.2 Les modèles de mesure du risque de crédit
15 D’après Altman et Saunders (1998), la mesure du risque de crédit a énormément évolué au cours des 20 dernières années. Cette évolution a été influencée par plusieurs facteurs. Parmi ceux-ci, les plus importants sont : une importante augmentation du nombre de faillites à travers le monde ; un accroissement de la désintermédiation financière chez les grandes entreprises (i.e., un accès direct de celles-ci aux marchés des capitaux), un marché du crédit plus compétitif ; le déclin de la valeur des biens mis en garantie, une forte croissance des instruments financiers hors bilan (qui ont très souvent leur propre risque endogène de défaut de la contrepartie). Face au changement du contexte économique induit par cette évolution, les académiciens et praticiens ont réagi : en développant des modèles de notation de crédit plus sophistiqués et des modèles de mesure du risque de crédit des instruments financiers hors bilan ; en ne s’intéressant plus uniquement au risque de crédit des prêts individuels, mais en adoptant une approche portefeuille des modèles de mesure du risque des prêts.
16 L’approche portefeuille de la modélisation du risque de crédit prend de plus en plus d’essor, et est aujourd’hui au centre de la majorité des modèles de mesure du risque de crédit. Cette tendance ne semble toutefois pas reléguer aux oubliettes les modèles d’estimation du risque, basés sur un score « credit scoring ». Ceux-ci semblent encore avoir de beaux jours devant eux car plusieurs modèles récents sont basés sur les informations de marché dont ne disposent pas toujours les emprunteurs individuels et les petites et moyennes entreprises.
1.2.1. Les modèles statistiques de notation de crédit
17 Les modèles de notation de crédit se basent généralement sur des techniques statistiques pour établir un score associé à l’entité évaluée. Des variables financières (essentiellement des ratios financiers) et non financières sont combinées pour générer un score ou une mesure de la probabilité de défaut de l’emprunteur. Ce score est alors comparé à un score critique. S’il lui est supérieur, le risque de l’entité évalué est jugé acceptable. Sinon le client est soumis à des analyses plus approfondies, ou la demande de prêt est tout simplement rejetée. Il existe au moins quatre systèmes multivariés de notation de crédit : 1. le modèle de régression ; le modèle « logit » qui utilise la probabilité logistique ; 3. le modèle « probit » et l’analyse discriminante.
18 L’analyse discriminante a été la méthodologie dominante (voir Altman, 1968 ; Altman, Haldeman et Narayanan, 1977 ; Altman, Avery, Eisenbeis et Sinkey, 1981 entre autres). Dans sa forme la plus simpliste, elle tente essentiellement de trouver une fonction linéaire pour les variables comptables et non comptables qui distinguent le mieux entre deux groupes d’emprunteurs, c’est-à-dire ceux qui vont honorer leurs créances et ceux qui ne vont pas rembourser leur emprunt. Elle se base sur le principe de la maximisation de la variance entre les deux groupes tout en minimisant la variance au sein d’un même groupe. Le modèle d’analyse discriminante le plus connu est sans doute celui élaboré par Altman, Haldeman et Narayanan en 1977 intitulé le « Zeta analysis ». Le modèle logit talonne l’analyse discriminante en terme de popularité. Il utilise un ensemble de variables comptables pour prédire la probabilité de défaut future d’un emprunteur, en supposant que ladite probabilité de défaut est distribuée logistiquement : la probabilité cumulée de défaut prend la forme d’une fonction logistique et est, par définition comprise entre 0 et 1.
1.2.2. Les modèles de notation de crédit basés sur l’intelligence artificielle
19 L’intelligence artificielle est souvent mise à contribution pour discriminer entre les bons et les mauvais dossiers de crédit. Les modèles courants dans ce chapitre incluent : le partitionnement récursif ; l’algorithme génétique et les réseaux de neurones.
20 Le partitionnement récursif est une technique itérative et non paramétrique. Le modèle prend la forme d’arbre de classification binaire dont les étapes de construction sont les suivantes : construction d’un univers de questions binaires ; sélection des meilleures questions qui optimisent la classification des entreprises en minimisant la fonction d’impureté dans les nœuds terminaux ; affectation des nœuds terminaux aux groupes qui assurent la minimisation des coûts de mauvaise classification. Le partitionnement récursif a été appliqué par plusieurs auteurs à la notation du crédit, et est largement décrit dans ces articles : Frydman, Altman et Kao (1985), Makowski (1985), Coffman (1986), Carter et Catlett (1987), Boyle, Crook, Hamilton et Thomas (1992).
21 L’algorithme génétique est basé sur le principe fondamental de l’évolution naturelle de Darwin. Il commence par générer aléatoirement une assez grande population de solutions potentielles au problème sous étude. Cette population évoluera à travers les générations, jusqu’à ce que les individus (qui sont ici les solutions potentielles) convergent vers un niveau jugé optimal. L’évolution se réalise en sélectionnant les meilleurs individus de chaque génération. Ces derniers entameront l’étape de la reproduction en combinant leurs gênes pour obtenir une nouvelle population d’individus qui évoluera à son tour de la même façon, jusqu’à ce qu’on aboutisse à une génération jugée optimale. Bien qu’utilisant le hasard, les algorithmes génétiques ne sont pas purement aléatoires. Ils suivent des lois probabilistes. Bauer (1994) fait une bonne description de la méthode. Varetto (1998) a été l’un des premiers à les utiliser dans la prévision de la faillite.
22 Les réseaux de neurones artificiels sont inspirés des systèmes neurobiologiques. Cette méthode non paramétrique issue du domaine des sciences cognitives s’inspire du fonctionnement du cerveau humain. Elle reçoit l’information, l’analyse et réagit en transmettant ou non un signal à un autre neurone. La particularité de la méthode des réseaux de neurones est basée sur le fait qu’elle explore les corrélations potentielles entre les différentes variables explicatives. Celles-ci sont alors exploitées comme variables additionnelles dans la fonction non linéaire de prévision de la faillite. Parmi les études qui ont incorporé l’analyse par réseaux de neurones dans un modèle de prévision de la faillite, on note Coats et Fant (1993), Tam et Kiang (1993), Back, Laitinen et Sere (1996), Zhang, Hu, Patuwo et Indro (1999).
1.2.3. Les modèles intégrant des variables de marché et l’approche portefeuille
23 Cette classe de modèles utilise soit exclusivement des données de marché ou les combine avec des données comptables. La forme la plus simple, est basée sur la théorie des options (Black et Scholes, 1973 ; Merton, 1974). La probabilité pour une firme de faire faillite dépend alors essentiellement de la valeur de ses dettes (B), de la valeur marchande de ses actifs (A) et de la volatilité de cette valeur marchande (?A). Ces deux derniers paramètres sont non observables et sont estimés simultanément. Le modèle Credit Monitor de KMV appartient à cette catégorie. Il utilise les valeurs de B, A et A pour calculer la distance du défaut (DD), laquelle est ensuite traduite en une fréquence de défaut anticipée (Expected Defautlt Frequency ou EDF). Cette EDF est calibrée de façon à équivaloir au pourcentage historique de défauts empiriquement observé. [5]
24 Longtemps négligée, la dimension portefeuille est de plus en plus présente dans l’estimation du risque de crédit. Les modèles d’estimation du risque de crédit d’un portefeuille de prêts peuvent être classés en deux catégories : les modèles analytiques, qui se basent sur un ensemble d’hypothèses pour fournir une solution « exacte » à la distribution des pertes sur actifs et les modèles basés sur la simulation, pour les cas où une solution analytique ne peut être trouvée. Parmi les modèles commercialisés on retrouve CreditMetrics de JP Morgan (l’analyse de migration y joue un rôle central), Portfolio Manager de KMV (qui est très similaire à CreditMetrics de JP Morgan, à la différence qu’il se focalise sur le défaut), Portfolio Risk Tracker de Standard & Poor (qui est une approche dynamique prenant en compte à la fois le défaut, la transition et les écarts stochastiques de taux d’intérêt), CreditPortfolioView (qui a la particularité de rendre les matrices de transition fonction de variables macro-économiques) et CreditRisk + de Credit Suisse First Boston (qui se base sur une démarche actuarielle du risque de crédit et capture uniquement les événements de défaut). Le tableau 1 fait un résumé des principales caractéristiques de ces différents modèles de risque de crédit du portefeuille.
Comparaison des modèles d’estimation du risque de crédit d’un portefeuille.
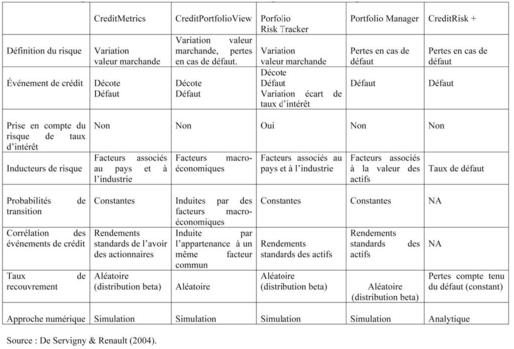
Comparaison des modèles d’estimation du risque de crédit d’un portefeuille.
2. Données et méthodologie de recherche
25 Un autre objectif de cette étude est de tester l’efficacité relative de quatre modèles de prévision de l’insolvabilité. Cependant, ne disposant pas de données sur les prêts bancaires, nous avons procédé indirectement, en utilisant un échantillon composé d’entreprises en faillite et d’entreprises saines. Nous avons alors fait des prévisions de faillite, selon l’hypothèse qu’une entreprise qui fera faillite sera généralement en défaut sur ses obligations. La base de données est constituée de 144 entreprises américaines provenant de plusieurs secteurs d’activités. Parmi celles-ci, 72 entreprises ont fait faillite entre 1980 et 1997. Les données proviennent de Compustat. Pour chaque entreprise, sept ratios financiers ont été sélectionnés comme variables explicatives. Il s’agit des mêmes ratios que ceux utilisés par Altman et al. (1977) dans le modèle « Zeta-analysis ».
26 Ils sont calculés pour les 144 entreprises de notre échantillon et ce, une année avant la faillite pour les entreprises qui ont fait faillite. Ces ratios sont les suivants :
- X1 = Bénéfice avant intérêts et impôts/Actif total (Mesure de la profitabilité) ;
- X2 = Écart — type de X1 (Mesure de la stabilité des rendements) ;
- X3 = Bénéfice avant intérêts et impôts + intérêts/intérêts (Ratio de couverture des intérêts) ;
- X4 = Bénéfices non répartis/Actif total (Mesure de la profitabilité cumulative de l’entreprise. Il donne une idée sur son âge, sa rentabilité et sa politique de dividendes) ;
- X5 = Actif à court terme/Passif à court terme (Mesure de liquidité) ;
- X6 = Capitalisation boursière/Capital total (Valeur marchande avoir des actionnaires) et
- X7 = Log [actif total] (Mesure de la taille).
28 Plusieurs logiciels ont été utilisés dans le processus. Il s’agit de : Xlstat pour l’analyse discriminante multivariée ; Cart pour le partitionnement récursif ; Evolver pour l’algorithme génétique et Neuroshell pour les réseaux de neurones.
29 Pour tester l’efficacité des modèles retenus, nous avons eu recours à la technique de la validation croisée. Elle consiste, lors de l’étape d’estimation du modèle (encore appelée période d’apprentissage), à laisser de côté une partie de l’échantillon de base qui servira par la suite à tester son pouvoir prédictif.
30 Nous avons divisé les 144 observations de notre échantillon en six sous-groupes comprenant chacun 24 entreprises, soit 12 entreprises défaillantes et 12 entreprises saines. Chaque modèle a été testé six fois. Dans chaque test, les données de cinq sous-groupes (120 observations) ont été utilisées pour estimer les paramètres du modèle (phase « Apprentissage »). Celles du sixième sous-groupe (24 observations) ont servi quant à elles à tester la validité du modèle. Les taux de bonne classification figurent dans la partie « Test de validation » du tableau associé à chaque méthode (voir annexes). Pour chacun d’eux, nous avons calculé le taux moyen de bonne classification, qui est la moyenne des six tests de validation croisée. Leur variance a aussi été calculée. Elle mesure la stabilité des résultats à travers les six tests de validation. Finalement, nous avons calculé la performance ajustée, que nous définissons par le ratio du taux moyen de bonne classification sur son écart type.
3. Résultats et analyses
31 Le tableau 2 fait une synthèse des taux finaux de bonne classification de chacun des quatre modèles testés, de leur variance et de la performance ajustée. [6]
Synthèse des résultats par modèle.

Synthèse des résultats par modèle.
32 Les résultats montrent que, lorsque la variabilité n’est pas prise en compte, le modèle qui se démarque en terme de pouvoir de prévision de la faillite est celui des réseaux de neurones artificiels, avec un taux moyen de bonne classification (calculé à partir des tests de validation croisée) de 79,86 %. Le deuxième modèle le plus performant est l’analyse discriminante multivariée avec un taux de 71,53 %. Il est suivi de l’algorithme génétique (70,08 % de bonne classification) et du partitionnement récursif (66,52 % de bonne classification).
Taux de bonne classification pour l’analyse discriminante multivariée.

Taux de bonne classification pour l’analyse discriminante multivariée.
Taux de bonne classification pour l’algorithme génétique.

Taux de bonne classification pour l’algorithme génétique.
33 Nous remarquons toutefois que les modèles ayant obtenu les taux moyens de bonne classification les plus faibles présentent aussi les résultats les plus stables. La variance des résultats des six tests de validation est de 0,25 % pour le partitionnement récursif et de 0,95 % pour l’algorithme génétique. Les variances des résultats des réseaux de neurones (1.21 %) et de l’analyse discriminante (2.74 %) sont relativement plus élevées.
34 Un bon modèle de prévision de l’insolvabilité (ou de la faillite) devrait se caractériser tant par un taux élevé de bonne classification que par une variance peu élevée. Pour chacun des 4 modèles, nous avons retenu le coefficient de variation des résultats (taux moyen de bonne classification/écart type des taux de bonne classification) comme mesure de performance ajustée. Il ressort de ce critère que le partitionnement récursif obtient le meilleur score (13,30), suivi des réseaux de neurones artificiels (7,26), de l’algorithme génétique (7,22) et de l’analyse discriminante (4,32).
35 D’après nos résultats, les trois modèles basés sur l’intelligence artificielle semblent prendre le dessus sur l’analyse discriminante. Contrairement à l’analyse discriminante, ils présentent l’avantage d’être des modèles non paramétriques, qui ne font aucune hypothèse quant à la distribution des variables explicatives utilisées. L’analyse discriminante est par contre une méthode statistique paramétrique. Les variables explicatives qu’elle utilise doivent respecter certaines hypothèses de départ, telle que la normalité. Ces hypothèses ne sont généralement pas respectées dans la pratique. C’est d’ailleurs la principale critique qui est faite à cette méthode dans la littérature financière.
Taux de bonne classification pour le partionnement récursif.
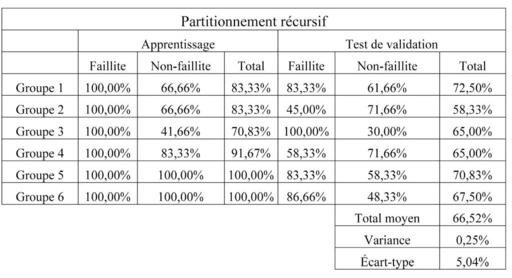
Taux de bonne classification pour le partionnement récursif.
Taux de bonne classification pour les réseaux de neurones artificiels

Taux de bonne classification pour les réseaux de neurones artificiels
Conclusion
36 Le but de la présente étude était de faire une analyse descriptive du processus d’analyse du crédit et de comparer la performance relative de quatre modèles de prévision de l’insolvabilité, à savoir l’analyse discriminante, le partitionnement récursif, l’algorithme génétique et les réseaux de neurones artificiels.
37 Nous avons, à travers le texte, présenté les différentes facettes et étapes de traitement d’une demande de crédit. Cet exposé est utile pour le banquier, ou pour tout autre prêteur. Il sert aussi aux clients en général, et en particulier aux individus ainsi qu’aux petites et moyennes entreprises, qui ne savent pas toujours comment s’y prendre avec leur banquier.
38 La comparaison de la performance des quatre modèles cités ci-dessus nous indique que, sur la base des données qui ont servi aux estimations, le partitionnement récursif obtient le meilleur score (13,30). Il est suivi des réseaux de neurones artificiels (7,26), de l’algorithme génétique (7,22) et de l’analyse discriminante (4,32). L’analyse présente toutefois une principale limite. En effet, plutôt que de tester le pouvoir prédictif des modèles sur les données d’insolvabilité de clients des banques -dont nous ne disposions pas- nous avons procédé indirectement, à travers une prévision de la faillite. Il serait donc intéressant de reprendre cette étude en utilisant un échantillon constitué essentiellement de clients (insolvables et solvables) de banques.
Références bibliographiques
- Altman, E.I. 1968. « Financial ratios, discriminant analysis and the prediction of corporate bankruptcy », Journal of Finance 23, p. 589-609.
- Altman, E.I. 1980. « Commercial bank lending : Process, credit scoring and costs of errors in lending », Journal of Financial and Quantitative Analysis 15, p. 813-832.
- Altman, E.I., et Saunders, A. 1998. “Credit risk measurement : Developments over the last 20 years », Journal of Banking and Finance 21, p. 1721-1742.
- Altman, E.I., Avery, R.B., Eisenbeis, R.A., et Sinkey, J.-F. 1981. “Discriminant analysis », Application of classification techniques in business, banking and finance, JAI Press, 1981, p. 33-57.
- Altman, E.I., Haldeman, R.G., et Narayanan, P. 1977. « Zeta analysis : A new model to identify bankruptcy risk of corporations », Journal of Banking and Finance 1, p. 29-54.
- Black, F., et Scholes, M. 1973. “The pricing of options and corporate liabilities », Journal of Political Economy 80, p. 637-659.
- Back, B., Laitinen, T., et Sere, K. 1996. “Neural networks and genetic algorithms for bankruptcy predictions », Expert Systems with Applications 11, p. 407-413.
- Barrickman, J. 2003. “The loan policy : Strategic plan for the lending function », The Risk Management Association Journal, April 2003, p. 88-91.
- Bartlett, C.M. 2000. « Credit process basics », Commercial Lending Review 15, p. 66-69.
- Bauer, R.J. Jr. 1994. “Genetic algorithm : Step by step », Genetic Algorithms and Investment Strategies, 1994, John Wiley & Sons, chap. 6, p. 55-71.
- Boyle, M., Crook, J.N., Hamilton, R., et Thomas, L.C. 1992 « Methods for credit scoring applied to slow players ». In Credit scoring and credit control (eds L.C. Thomas, J.N. Crook et D.B. Eleman), p. 75-90. Oxford : Clarendon.
- Carter, C., et Catlett, J. 1987. “Assessing credit card applications using machine learning. IEEE Expert. p. 71-79.
- Catanach, A.H. Jr., Kemp, R.S., et Pettit L.C. 2000. « Proper Loan Structure : The Key to Creating Bank Value », Commercial Lending Review 15, p. 43-47.
- Coats, P.K., et Fant, L.F. 1993. « Recognizing Financial Distress Patterns Using a Neural Network Tool », Financial Management 22, p. 142-155.
- Coffman, J.Y. 1986. “The proper role of tree analysis in forecasting the risk behaviour of borrowers », MDS reports 3,4,7, and 9. Management Decision Systems, Atlanta.
- Cohen, J.K., Gilmoure, T.C., et Singer, F.A. 1966. « Bank procedures for analyzing business loan applications », Analytical methods in banking, in Cohen and Hammer (Eds.), 1966, p. 218- 251.
- De Servigny, A., et Renault, D. 2004. Measuring and Managing Credit Risk, McGraw Hill, 466 pages.
- Frydman, H.E., Altman, E.I. et Kao, D.L. 1985. « Introducing recursive partioning for financial classification : The case of financial distress », Journal of Finance, p. 269-291.
- Makowski, P. 1985. « Credit scoring branches out », Credit World 75, p. 30-37.
- Merton, R.C. 1974. « On the pricing of corporate debt : The risk structure of interest rates », Journal of Finance 29, p. 449-470.
- Morsman, E.M. Jr. 2002. “Commercial loan structure », The Risk Management Association Journal, July-August, p. 27-37.
- Tam, K.Y., et Kiang, M.Y. 1993. « Managerial applications of neural networks : The Case of bank failure predictions », Neural Networks, Probus, p. 193-228.
- Varetto, F. 1998. “Genetic algorithms applications in the analysis of insolvency risk », Journal of Banking and Finance 22, p. 1421- 1439.
- Zhang, G., Hu, M.Y., Patuwo, B E., et Indro, D.C. 1999. « Artificial neural networks in bankruptcy prediction : General framework and cross-validation analysis », European Journal of Operational Research 116, p. 16-32.
Mots-clés éditeurs : algorithme génétique, analyse discriminante, comparaison, Décision de crédit, partitionnement récursif, prévision d'insolvabilité, réseaux deneuronnes
Date de mise en ligne : 01/05/2011
https://doi.org/10.3917/rsg.224.0177