Les mégadonnées et l’essor de l’intelligence artificielle
Pages 68 à 76
Citer cet article
- CLÉMENÇON, Stéphan,
- Clémençon, Stéphan.
- Clémençon, S.
https://doi.org/10.3917/cafr.419.0068
Citer cet article
- Clémençon, S.
- Clémençon, Stéphan.
- CLÉMENÇON, Stéphan,
https://doi.org/10.3917/cafr.419.0068
Notes
-
[1]
Xarren McCulloch et Walter Pitts (1943), “A Logical Calculus of Ideas Immanent in Nervous Activity”, Bulletin of Mathematical Biophysics, vol. 5 (4), p. 115-133.
-
[2]
Frank Rosenblatt (1958), “The Perceptron : A Probabilistic Model for Information Storage and Organization in the Brain”, Cornell Aeronautical Laboratory, Psychological Review, vol. 65 (6), p. 386– 408.
L’intelligence artificielle (IA) réside essentiellement aujourd’hui en un traitement mathématique sophistiqué de masses d’informations numérisées. Si les opportunités qu’elle offre suscitent l’enthousiasme, les enjeux d’éthique, d’équité, de fiabilité, d’interprétabilité ou encore d’explicabilité sont toutefois considérables.
1 En faisant la démonstration d’une maîtrise alors inédite des sciences et technologies de l’information, les grandes entreprises du web nous ont montré le chemin il y a plus de vingt ans déjà : nous vivons désormais à l’ère du big data. On parle aussi de mégadonnées pour décrire ces données aux formats divers, collectées et stockées en masse, souvent en temps quasi continu, au moyen des infrastructures informatiques modernes. Le développement de l’internet, l’avènement des réseaux sociaux, l’omniprésence de capteurs connectés disséminés dans notre environnement (l’internet des objets), l’élaboration d’instruments de mesure de pointe, de la spectrométrie de masse aux télescopes spatiaux, nous donnent toujours plus à voir : phénomènes physiques, comportements sociaux, processus biologiques…
2 L’accès à une information massive, sous forme numérique, transforme rapidement l’activité humaine dans presque tous les secteurs : science, commerce, médecine, sécurité, transports, énergie, banque/assurance… Elle offre la promesse de l’intelligence artificielle généralisée, c’est-à-dire du déploiement ubiquitaire de machines nourries par les masses de données, et capables d’effectuer des tâches diverses avec une grande efficacité et de façon autonome. La disponibilité d’une information à la granularité toujours plus fine aurait de multiples applications. Elle pourrait notamment élaborer des solutions de maintenance prédictive pour les infrastructures sophistiquées, des réseaux de transport d’énergie ou des avions par exemple (voir par exemple la surveillance des centrales électriques chez General Electric).
3 Les champs d’application sont en effet innombrables (Capgemini Research Institute, Scaling AI in Manufactoring Operations, a Practitioners’ Perspective, 2019): l’analyse automatique de « signaux faibles », annonciateurs de pannes ou de dysfonctionnements, détectés suffisamment tôt, conférerait une pérennité accrue au service prodigué en anticipant le remplacement des composants du système avant une défaillance probable (voir le cas des infrastructures ferroviaires). Une médecine offrant un haut degré de personnalisation et une efficacité plus importante, en adaptant le traitement aux caractéristiques génétiques et environnementales du patient, pourrait aussi voir le jour grâce à l’intelligence artificielle. Aujourd’hui déjà, celle-ci est déployée dans des domaines divers et s’incarne dans de très nombreuses applications : les systèmes performants de reconnaissance biométrique équipant les aéroports, le véhicule à délégation partielle (les voitures dites semi-autonomes), les assistants personnels virtuels, la vidéosurveillance ou les moteurs de recommandation des portails web par exemple.
Utilisation par l’armée américaine d’un système de contrôle biométrique : la reconnaissance de l’iris à l’aide d’une caméra numérique

Utilisation par l’armée américaine d’un système de contrôle biométrique : la reconnaissance de l’iris à l’aide d’une caméra numérique
La spectrométrie mesure des grandeurs physiques associées à un spectre et permet ainsi d’accéder à la composition et à la structure de la matière.
Dans la collection Doc en poche est sorti le 9 décembre 2020 : Rodolphe Gelin, Olivier Guilhem, L’intelligence artificielle, avec ou contre nous ? Livre blanc et livre noir de l’IA, La Documentation française, 2020.
6 Les questions scientifiques restent certes très nombreuses, l’aventure ne faisant que commencer, mais les opportunités offertes par l’intelligence artificielle sont incontestables. L’enthousiasme paraît en effet fondé, tant la technologie actuelle rend possible la mise en œuvre de traitements mathématiques sophistiqués des masses d’informations numérisées. Dans le même temps, l’intelligence artificielle est souvent perçue comme une menace pour l’emploi, le respect de la vie privée ou le contrôle des décisions lorsqu’elles sont prises par des systèmes considérés comme des « boîtes noires » (Yoshua Bengio, « Learning Deep Architectures for AI », Foundations and Trends in Machine Learning, vol. 2, n° 1, p. 1-127, 2009). Les dispositifs automatisés fondés sur ce corpus de méthodes sont ainsi parfois accusés de produire des résultats erronés, les données sur lesquelles reposent leurs décisions, pouvant par exemple être biaisées par des erreurs de mesure ou « contaminées » avec une volonté de nuire comme lors de la campagne présidentielle aux États-Unis en 2016. Ils pourraient même accroître certains types de discriminations, ainsi qu’en attestent les débats récents autour du caractère supposé raciste ou sexiste de certaines applications telles que des agents conversationnels, des logiciels de police prédictive, des programmes de recommandation ou des systèmes de reconnaissance faciale. Les risques sont en effet bien réels, d’autant plus que les plateformes technologiques modernes permettent un usage immédiat de certaines solutions logicielles (par exemple des outils numériques d’aide à la décision). L’intelligence artificielle ne tiendra ses promesses que si les enjeux d’éthique, d’équité, de fiabilité, d’interprétabilité ou encore d’explicabilité sont considérés au même niveau que la recherche de la simple efficacité. S’il est encore difficile de savoir comment concevoir une régulation efficace sans brider l’innovation, nul doute que la maîtrise des risques passe en partie par l’éducation et la formation, la diffusion d’une « culture des données et des algorithmes » auprès d’un large public (Cathy O’Neil, Algorithmes : la bombe à retardement, Les Arènes, Paris, 2018, 352 p).
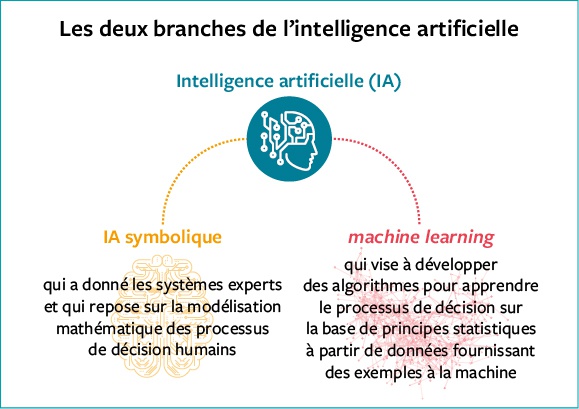
Machine learning : la statistique au service de la prédiction
7 Les craintes liées à l’automatisation ne sont pas nouvelles et, en ce qui concerne le traitement des masses d’informations numérisées, cette automatisation, si elle doit bien sûr s’effectuer de façon contrôlée, est non seulement inévitable mais aussi souhaitable (National Research Council, Frontiers in Massive Data Analysis, Washington D. C., The National Academies Press, 2013). Elle peut être perçue de façon erronée comme une discipline dont l’ambition est de remplacer l’expertise d’un opérateur humain dans tous les domaines par des robots effectuant des tâches automatisées définies par des données. En réalité, le machine ou statistical learning (l’apprentissage statistique) a pour but de nous aider à exploiter « l’information massive », issue des masses de données, et collectée par les capteurs modernes et dont la complexité est telle qu’il nous serait tout à fait impossible de l’embrasser sans un traitement mathématique approprié, réalisé au moyen de programmes informatiques dédiés. Ce domaine scientifique et technique est la branche de l’intelligence artificielle sur laquelle toute l’attention se focalise aujourd’hui.
Zoom
Il s’agit d’un corpus de méthodes permettant à une machine de prendre une décision sur la base de données. Lors de la phase d’« entraînement », des données comprenant à la fois l’information en entrée du système et la décision attendue sont présentées à la machine afin qu’elle « apprenne » une règle de décision. Lors de la phase de « test », seule l’information d’entrée est disponible et la machine prend ses décisions sur la base de celle-ci uniquement, de façon autonome. Les données d’apprentissage, même si elles sont disponibles en très grande quantité, ne représentent qu’un échantillon de la réalité, des situations rencontrées ultérieurement en phase de test. Le recours à la science probabiliste est donc nécessaire pour fournir des garanties à l’efficacité du procédé. Par ailleurs, les données sur lesquelles la machine doit s’exprimer doivent suivre la même loi de probabilité que les données d’apprentissage, sinon les garanties d’efficacité ne tiennent plus.
À titre d’exemple, dans le modèle neuronal le plus simple [1], un neurone formel (modélisation mathématique schématique d’un neurone biologique) agrège l’information numérique qui lui est transmise (à la manière de la transmission synaptique de l’information vers les neurones biologiques) en calculant un produit scalaire (une somme pondérée, c’est-à-dire une succession de multiplications et d’additions). La décision binaire attendue dépendra de l’activation du neurone, il est activé si le produit scalaire est positif. Lors de la phase d’apprentissage, les poids sont appris par la machine de façon à produire un maximum de décisions correctes sur les données d’entraînement [2].

Les origines du machine learning
8 À l’interface des mathématiques et de l’informatique et largement inspiré par les sciences cognitives, le machine learning s’est en partie développé avec les travaux précurseurs des mathématiciens russes Vladimir Vapnik et Alexey Chervonenkis (Vladimir Vapnik, The Nature of Statistical Learning Theory, Springer, New York, 1995). Initiés il y a près de soixante ans, ils ont participé à faire naître un champ interdisciplinaire mobilisant une communauté très dynamique de spécialistes, aujourd’hui en pleine expansion. La maîtrise des algorithmes d’apprentissage statistique requiert certes des connaissances avancées dans les domaines des mathématiques appliquées et de l’informatique. Cependant, la compréhension des concepts essentiels à l’œuvre dans des technologies largement déployées et mises fréquemment en avant pour illustrer les succès de l’intelligence artificielle, comme la vision par ordinateur, la reconnaissance de la parole ou de l’écriture manuscrite, est à la portée de nombreux citoyens, dont la réflexion peut s’appuyer sur des acquis relativement élémentaires en mathématiques et en informatique.
9 Les paradigmes du machine learning peuvent en effet être aisément décrits à travers les principes statistiques de la « reconnaissance des formes », établis au siècle dernier, plusieurs décennies avant que des avancées technologiques spectaculaires, dans les domaines de la collecte et du stockage de données et du calcul intensif, ne nous permettent de les appliquer efficacement (Christopher Bishop, Pattern Recognition and Machine Learning, Springer, New York, 2006). Dans ce type de problème, le robot (la machine) doit accomplir la tâche suivante : à partir de données d’entrée, il doit reconnaître automatiquement la catégorie, l’étiquette (d’un type de donnée spécifiée à l’avance) associée à l’objet/individu décrit par les données d’entrée avec un risque d’erreur minimal. On a recours à l’apprentissage statistique lorsque la complexité des relations entre l’entrée et la sortie du système rend toute modélisation experte (c’est-à-dire humaine) inopérante.
Comment fonctionne l’apprentissage statistique ?
10 Même si elle se formule de façon très simple, la problématique couvre de très nombreuses applications : reconnaissance biométrique, diagnostic/pronostic médical assisté, credit-scoring (pour analyser les demandes de crédits)… Dans le cas de la vision par ordinateur par exemple, une image pixellisée sera présentée en entrée et une étiquette associée à l’image indique en sortie la présence éventuelle d’un objet spécifique dans celle-ci. Ce problème est de nature prédictive. La règle de décision déterminée par un algorithme d’apprentissage opère en effet sur une base de données étiquetées (i. e. les « données d’apprentissage »). Celle-ci ne doit pas seulement pouvoir être mise en œuvre au moyen des outils de calcul scientifique disponibles aujourd’hui de façon à minimiser l’erreur commise sur les données d’apprentissage (il est en effet toujours facile de « prédire le passé »). Il s’agit aussi de s’assurer que, lorsque la règle sera déployée, la machine continue à prédire efficacement le label associé à de nouvelles données d’entrée, non encore observées. On dira le cas échéant que la règle prédictive a alors de « bonnes capacités de généralisation ». Le langage des probabilités et des statistiques, particulièrement adapté pour raisonner en univers incertain et décrire la variabilité des données, permet de formaliser ce problème rigoureusement.
Le principe statistique de la reconnaissance des formes décrit un ensemble de techniques et méthodes visant à identifier des motifs informatiques à partir de données brutes afin de prendre une décision.
12 Par la suite, des images seront présentées aléatoirement à la machine, laquelle décidera à chaque fois si l’objet spécifique considéré est présent ou non dans l’image. Le risque d’erreur que l’on voudrait minimiser au moyen de la technique d’apprentissage est la probabilité de prédire de façon erronée l’étiquette relative à une image présentée aléatoirement en entrée à la machine. Cette probabilité d’erreur est en pratique inconnue, la base de données d’apprentissage étant souvent loin de rendre compte de l’« univers de tous les possibles », de contenir toutes les paires entrée-sortie pour lesquelles la machine aura à effectuer une prédiction dans le futur. Ce que l’on entend exactement par « apprentissage » d’une règle de décision par la machine consiste en la mise en œuvre d’un programme d’optimisation. Son objectif est de minimiser une version statistique du risque d’erreur calculée à partir de la base de données d’entraînement (la fréquence des erreurs commises sur les exemples d’apprentissage dans le cas le plus simple) en opérant sur une classe de règles donnée.
13 Les travaux mathématiques de V. Vapnik et A. Chervonenkis offrent un cadre de validité aux techniques de minimisation du risque empirique. Ils garantissent de bonnes capacités de généralisation à la règle prédictive issue de la procédure d’apprentissage, lorsque la classe de règles sur laquelle est opérée l’optimisation est de complexité contrôlée. Cette classe de règles doit aussi être suffisamment riche pour contenir des règles s’ajustant bien aux données, pourvu que le nombre d’exemples d’apprentissage présentés à la machine soit suffisamment grand pour que le risque d’erreur théorique puisse être approché par sa version statistique. Ce n’est qu’à l’aide de cet ensemble de conditions que l’apprentissage statistique donne des résultats satisfaisants et acceptables pour la société.
Recueil de données sur des individus et des véhicules, au sein d’une ville intelligente. Leur analyse sera facilitée par l’emploi de l’apprentissage automatique (machine learning).

Recueil de données sur des individus et des véhicules, au sein d’une ville intelligente. Leur analyse sera facilitée par l’emploi de l’apprentissage automatique (machine learning).
Big data ou la prédiction à l’aide de la loi des grands nombres
14 Ces concepts fondamentaux, ainsi que certaines approches algorithmiques telles que les réseaux de neurones artificiels – des modèles mathématiques dont la structure évoque celle des neurones biologiques du cerveau humain et modélisant les mécanismes d’apprentissage et de décision qui s’y produisent –, sont décrits dans la littérature scientifique dès la fin des années 1970 (M. Minsky et S. Papert, Perceptrons : An Introduction to Computational Geometry, 2e édition, The MIT Press, Cambridge MA, 1972, 268 p). Ce n’est cependant qu’avec le big Data que le machine learning a commencé à rencontrer le succès. On peut expliquer son échec temporaire d’une part par la rareté de l’information numérisée disponible à l’époque, la collecte de données d’entraînement s’effectuaient généralement au moyen de questionnaires très coûteux, engendrant une erreur statistique parfois considérable. D’autre part, cet échec temporaire s’explique aussi par des capacités de mémoire et de calcul alors très limitées. À l’époque, les programmes d’optimisation pouvant être mis en œuvre opéraient sur des classes de règles trop frustes pour réaliser un apprentissage efficace.
Zoom
On les appelle parfois données massives ou simplement mégadonnées. Mais en réalité, la notion désigne rarement les données en soi, et recouvre plutôt l’utilisation qui en est faite. On leur prête ainsi trois caractéristiques, les trois « V ».
Le volume bien sûr, mais aussi la variété : les données ne consistent pas seulement en ces matrices de nombres qu’aiment analyser les statisticiens mais également en des sons, du texte, des images ou des interactions. La vélocité enfin : les contraintes de temps quasi-réel de certaines applications (comme la prévision du trafic routier) imposent de pouvoir analyser très rapidement des masses de données.
Si la grande volumétrie des big data peut apparaître comme une bénédiction, en réduisant l’incertitude statistique, elle confronte les méthodes d’analyse aux questions de passage à l’échelle et stimule la recherche méthodologique. Les travaux menés par la communauté scientifique concernent les aspects de variété des données, appelant de nouvelles représentations mathématiques de l’information comme les questions de vélocité, lesquelles requièrent la mise au point d’algorithmes toujours plus efficaces.
Stéphan Clémençon
15 Des progrès considérables ont été accomplis depuis, notamment grâce aux briques technologiques élaborées pour le développement du web. Combinés au perfectionnement des méthodes algorithmiques, ces avancées réalisées dans le domaine de la gestion de la mémoire, les systèmes de fichiers distribués du framework Hadoop ou le développement de langages de programmation tels que MapReduce permettent désormais des applications d’une ampleur inédite. Ils mettent en effet en œuvre des programmes de machine learning opérant sur des classes de règles prédictives très flexibles, telles que les réseaux de neurones profonds (deep learning), à partir de données massives, les immenses bibliothèques de contenus (c’est-à-dire images, sons, textes) disponibles sur le web en particulier. C’est ainsi que sont entraînés les moteurs de recherche et de recommandation, tellement présents dans notre quotidien. Ils sont nourris par un nombre vertigineux d’exemples étiquetés par leurs utilisateurs. Le big data permet en quelque sorte aux approches d’apprentissage statistique d’accéder au « paradis asymptotique » promis par la loi des grands nombres, le même principe que celui qui permet à un casino d’être bénéficiaire sur le long terme.
Hadoop est un framework open source écrit en Java destiné à faciliter la création d’applications, notamment dans le domaine du stockage de données.
Map Reduce est un composant d’Hadoop utilisé notamment dans le traitement de données potentiellement très volumineuses.
Les problèmes : les hypothèses et les contrôles
18 L’ubiquité des capteurs et le développement de l’internet des objets facilitent désormais l’accès à l’information numérique, et d’innombrables applications sont donc développées aujourd’hui sur le modèle de la reconnaissance de formes. Les infrastructures d’acquisition, de stockage des masses de données et de calcul ne conditionnent cependant pas, à elles seules, les progrès réalisés dans le domaine de l’intelligence artificielle. L’extrême facilité, du point de vue strictement opérationnel, avec laquelle il est désormais possible de collecter des données puis de les injecter dans un moteur de machine learning, tels que ceux proposés « en tant que service » par les géants du numérique depuis quelques années, ne doit pas faire oublier un point important : une procédure d’apprentissage statistique, aussi automatisable qu’elle soit, n’est valide que dans un cadre spécifique, qui dépend d’hypothèses sur les mécanismes aléatoires inhérents à l’observation des données et du catalogue de règles de décision jugées potentiellement performantes utilisé. Par ailleurs, il existe aussi le risque que ces procédures incitent certains à jouer à l’« apprenti sorcier ».
19 Ainsi, pour reprendre l’exemple précédent, la capacité de généralisation d’une règle produite par un algorithme standard de machine learning pour la reconnaissance de formes n’est assurée que dans les situations où les données, sur lesquelles elle est appliquée, suivent la même loi de probabilité que les données d’entraînement utilisées lors de l’étape d’apprentissage. Cette condition est en effet fondamentale. Si, par exemple, les images de la base d’entraînement contenant l’objet que l’on cherche à reconnaître correspondent à celles qui présentent un fond vert, on s’attendra naturellement à ce que le biais de sélection qui en résulte fasse que la machine apprenne à reconnaître la présence d’un fond vert plutôt que celle de l’objet. Mais au-delà de cet exemple aussi saisissant que simpliste, il convient de se rappeler que les big data, et les données du web en particulier, ne sont généralement pas obtenues à partir d’un plan d’expérience ou de sondage défini à l’avance. Certaines applications se contentent d’exploiter a posteriori l’information qui a pu être collectée sans toute la rigueur scientifique nécessaire, ignorant les questions méthodologiques relatives au traitement de biais induits par divers mécanismes (censure, troncature, instabilité du phénomène analysé au cours du temps, voir O’Neil, 2018, op. cit.), dont la maîtrise reste encore largement l’apanage de la statistique traditionnelle (voir : Institut Montaigne, Algorithmes, contrôle des biais S.V.P., mars 2020).
Portraits of Imaginary People, œuvre de Mike Tyka. Le portrait est généré par un réseau de neurones artificiels

Portraits of Imaginary People, œuvre de Mike Tyka. Le portrait est généré par un réseau de neurones artificiels
Selon le théorème de la loi des grands nombres des probabilistes, dans une longue suite de tirages à pile ou face, environ la moitié tombent sur face.
En mars 2016, le programme informatique AlphaGo, utilisant l’apprentissage par renforcement pour s’améliorer, sort victorieux du match de go l’opposant au champion sud-coréen Lee Sedol

En mars 2016, le programme informatique AlphaGo, utilisant l’apprentissage par renforcement pour s’améliorer, sort victorieux du match de go l’opposant au champion sud-coréen Lee Sedol
21 Cette absence de contrôle sur le processus d’acquisition des données peut naturellement compromettre la découverte de régularités statistiques enfouies dans les masses de données. On se souviendra dans ce contexte des sérieuses déconvenues essuyées par certaines applications relatives à la prédiction des épidémies ou du trafic routier (A.Devillard, « Google arrête de prévoir mal les épidémies de grippe », Sciences et Avenir, 10 septembre 2015). Le contrôle du processus de collecte des données et des hypothèses de validité des algorithmes prédictifs conditionne donc la pertinence des modèles calculés par les machines. Ce besoin est d’autant plus pressant que ces dernières sont programmées aujourd’hui de façon à ne plus se contenter simplement d’utiliser un historique de données mais afin qu’elles puissent également solliciter de nouvelles informations pour accroître l’efficacité de leurs décisions, réalisant un compromis délicat entre exploitation des données disponibles et exploration de l’univers des possibles. On parle d’apprentissage par renforcement lorsque le système « intelligent » interagit avec l’environnement qui engendre les données, ce type d’apprentissage étant à l’œuvre par exemple pour élaborer les nouvelles générations d’assistants virtuels ou de moteurs de recommandation (comme par exemple pour apprendre à conduire une voiture en une journée). Au-delà des approfondissements théoriques et méthodologiques nécessaires à l’élaboration de techniques d’apprentissage statistique plus fiables et plus robustes, d’une plus grande transparence quant à l’élaboration et au fonctionnement des modèles produits par le machine learning, il apparaît indispensable que l’inflation de « solutions technologiques » fondées sur l’analyse des masses de données, s’accompagne d’une plus grande diffusion de la culture probabiliste et statistique dans la plupart des cursus universitaires, et pas seulement dans celui de ces nouveaux spécialistes, les scientifiques des données (data scientists). La transmission de cette culture est sans aucun doute l’une des clefs pour que le citoyen ne se sente pas dépossédé de choix importants qui en appellent aux données et puisse résister aux éventuelles dérives.